BST 二叉搜索树 BinarySearchTree 递归/非递归实现
二叉搜索树
基本概念
二叉搜索树(BST,Binary Search Tree)
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
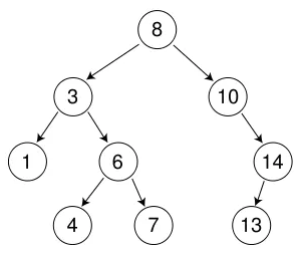
int a[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};
二叉搜索树/二叉查找树也称二叉排序树,因为二叉排序树的中序遍历结果是升序
常用结论
二叉搜索树的左子树一定小于根,右子树一定大于根,结合定义递归子树可以得到
-
左子树的最右节点是左子树的最大节点,右子树的最右节点是右子树的最大节点.
-
左子树的最左节点是左子树的最小节点,右子树的最左节点是右子树的最小节点.
-
二叉搜索树的最小节点是左子树的最左节点,最大节点是右子树的最右节点
用途
实际情况很少直接使用搜索二叉树,多是根据搜索二叉树的高效搜索特性,衍生出更为实用的高阶数据结构,例如平衡二叉搜索树(AVL树,红黑树)等...
- K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。(在不在的问题)
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
还有如:门禁系统,车库系统等...
- KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方
式在现实生活中非常常见: (通过一个值查找另一个值)
比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英
文单词与其对应的中文<word, chinese>就构成一种键值对;
再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出
现次数就是<word, count>就构成一种键值对。
还有如:通讯录
二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:

最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:$log_2 N$ ($log_2 N$)
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:$\frac{N}{2}$ ($\frac{N}{2}$)
二叉搜索树的操作
查找
- 从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。
- 最多查找高度次,走到到空,还没找到,这个值不存在。
插入
- 树为空,则直接新增节点,赋值给root指针(第一个节点就是root)
- 树不空,按二叉搜索树性质查找插入位置,插入新节点
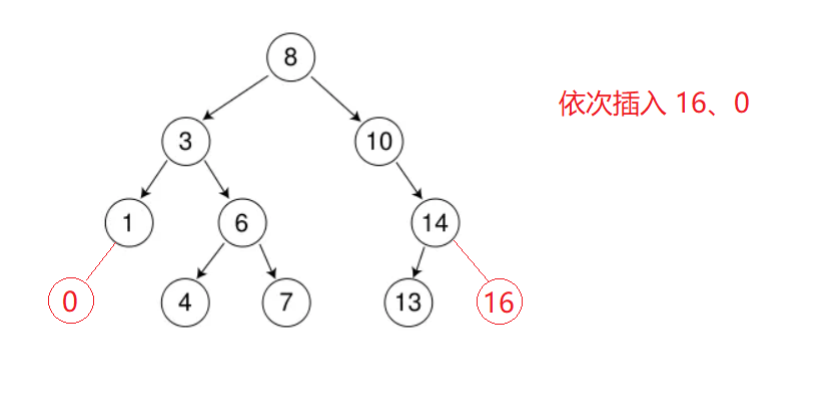
特别地
-
同样一组数据,插入顺序不同,得到的二叉树也不同
-
当插入的值已存在时,插入失败(不考虑multi)
删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回.
否则,根据树的结构定义,可以得到3种情况
- 要删除的结点无孩子结点
- 要删除的结点只有左孩子或右孩子时
- 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况:
-
要删除的结点无孩子结点时,直接删除
-
要删除的结点只有左孩子或右孩子时,将左孩子或右孩子给父亲
-
要删除的结点可能是父亲的左孩子或者是右孩子,有2*2种情况(要删除的结点是父亲的左孩子或右孩子)
-
左右孩子都是空时,也满足情况,因此可以合并无孩子结点情况
-
在1的前提下,恰好是根节点,也是一种情况(让另外一个孩子做根即可)
-
-
要删除的结点有左右孩子(子树)时,需要找一个既要比左子树大也要比右子树小的节点来补上.
根据递归定义得知,只有左孩子的最右结点和右孩子的最左结点符合条件,二选一即可
当选择使用右孩子的最左结点时,有以下三种情况(与是不是根无关)
-
要删除的结点的右子树的最小结点恰好是要删除结点的右孩子.
-
要删除的结点的右子树的最小结点没有右孩子.
-
要删除的结点的右子树的最小结点有右孩子

(上图举例分析)
-
代码实现
BSTree.hpp
template<class K>
struct BSTreeNode {
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(K key)
:_key(key),_left(nullptr),_right(nullptr)
{}
};
template<class K>
class BSTree {
public:
using Node = BSTreeNode<K>;
BSTree() = default;
BSTree(const BSTree& bst) {
_root = Copy(bst._root);
}
BSTree<K>& operator=(BSTree bst) { //拷贝复用
swap(_root,bst.root);
return *this;
}
~BSTree() {
Destroy(_root);
}
public:
bool Insert(const K& key) {
if (_root == nullptr) {
_root = new Node(key);
_root->_key = key;
return true;
}
BSTreeNode<K>* cur = _root;
BSTreeNode<K>* parent = _root;
while (cur) {
if (key < cur->_key) {
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key) {
parent = cur;
cur = cur->_right;
}
else {
return false;
}
}
//走出循环,说明树中不存在该节点, 可以插入
cur = new BSTreeNode<K>(key);
if (key < parent->_key) {
parent->_left = cur;
}
else {
parent->_right = cur;
}
return true;
}
bool Find(const K& key) {
if (_root == nullptr) return false;
Node* cur = _root;
while (cur) {
if (key < cur->_key) {
cur = cur->_left;
}
else if (key > cur->_key) {
cur = cur->_right;
}
else {
return true;
}
}
// 从循环出来,说明没找着
return false;
}
bool Erase(const K& key) {
if (_root == nullptr) return false;
Node* cur = _root;
Node* parent = _root;
while (cur) {
if (key < cur->_key) {
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key) {
parent = cur;
cur = cur->_right;
}
else {
//没有左孩子
if (cur->_left == nullptr) {
if (cur == _root) {
_root = cur->_right;
}
else if (parent->_left == cur) {
parent->_left = cur->_right;
}
else {
parent->_right = cur->_right;
}
delete cur;
return true;
}
//没有右孩子
else if (cur->_right == nullptr) {
if (cur == _root) {
_root = cur->_left;
}
if (parent->_left == cur) {
parent->_left = cur->_left;
}
else {
parent->_right = cur->_left;
}
delete cur;
return true;
}
//有左右孩子
else {
//找右孩子(子树)的最小结点/最左结点
Node* rightMin = cur->_right; //明确不为空
Node* rightMinParent = cur;
while (rightMin->_left) {
rightMinParent = rightMin;
rightMin = rightMin->_left;
}
// 删除右子树最小结点有3种情况(与是不是根无关)
//1. 要删除的结点右子树最小结点恰好是自己的右孩子.
//2. 要删除的结点的右孩子的左子树的最左结点没有右孩子.
//3. 要删除的结点的右孩子的左子树的最左结点有右孩子.
//结论解析: 复用删除单结点代码,进行删除rightMin即可
K tmp = rightMin->_key;
Erase(rightMin->_key); //只能从根开始遍历,性能损失,但是二分查找很快,损失不大(理想情况,BST只学习用)
cur->_key = tmp;
return true;
} //有左右孩子的情况
} //找到了_继续处理的过程
}//循环找的过程
//循环结束,说明没找到
return false;
}//Erase [end]
void InOrder() {
_InOrder(_root);
std::cout << std::endl;
}
bool InsertR(const K& key) {
_InsertR(_root, key);
}
bool EraseR(const K& key) {
return _EraseR(_root,key);
}
private:
//此处返回值不能使用指针引用,虽然一定情况下可以使用(不推荐),至少目前不能引用空值.
Node* Copy(const Node* root) {
if (root == nullptr) {
return nullptr;
}
Node* newRoot = new Node(root->_key);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
}
//用不用引用无所谓,好习惯做到底
//(析构子节点时,父节点两个成员会成为垂悬指针,但是接下来父亲也要析构了,指针变量也随之回收)
void Destroy(Node*&root) {
if (root == nullptr) {
return ;
}
Destroy(root->_left);
Destroy(root->_right);
std::cout<<root->_key<<" ";
delete root; //释放加自动置空
}
//练习递归+引用 -- 代码更加简洁
bool _EraseR(Node*& root, const K&key) {
//走到空,说明没找到,返回false
if (root == nullptr) {
return false;
}
//大于走右边,小于走左边
if (key > root->_key) {
return _EraseR(root->_right,key);
}
else if(key<root->_key) {
return _EraseR(root->_left,key);
}
//找到了
else {
if (root->_left == nullptr) {
Node* del = root;
root = root->_right;
delete del;
return true;
}
else if (root->_right == nullptr) {
Node* del = root;
root = root->_left;
delete del;
return true;
}
//有左右孩子
else {
Node* leftMax = root->_left;
//找左子树最大结点
while (leftMax->_right) {
leftMax = leftMax->_right;
}
std::swap(root->_key, leftMax->_key);
return _EraseR(root->_left, key); //直接从左孩子开始递归删除.
}
}
}
//练习递归+引用指针的玩法,仅练习
bool _InsertR(Node*& root, const K& key) { //引用的妙用,跨栈帧直接访问实参
if (root == nullptr) {
root == new Node(key);
return true;
}
if (key == root->_key) return false;
return (key > root->_key) ? _InsertR(root->_right, key) : _InsertR(root->_left, key);
}
void _InOrder(Node* root) {
if (root == nullptr) return;
_InOrder(root->_left);
std::cout << root->_key << " ";
_InOrder(root->_right);
}
private:
BSTreeNode<K>* _root = nullptr;
};
test.cc
void test() {
int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
BSTree<int> bst;
for (int i : a) {
bst.Insert(i);
}
bst.InOrder();
////Find
//std::cout << std::boolalpha << bst.Find(8) << std::endl; //true
//std::cout << std::boolalpha << bst.Find(9) << std::endl; //false
BSTree<int> cp(bst);
cp.InOrder();
//测试两孩子的三种情况即可
bst.Erase(8); //1. 要删除的结点的右子树的最小结点恰好是要删除结点的右孩子.
bst.Erase(10); //2. 要删除的结点的右子树的最小结点没有右孩子
bst.Insert(5); //构造有右孩子的最小结点
bst.Erase(3); //3. 要删除的结点的右子树的最小结点有右孩子
bst.Erase(4);
bst.Erase(7);
bst.Erase(1);
bst.Erase(14);
bst.Erase(13);
bst.Erase(6);
bst.Erase(5);
bst.InOrder();
//禁止显式调用析构函数 --> 双重释放
//bst.~BSTree();
//cp.~BSTree();
}
int main() {
test();
}
本文来自博客园,作者:HJfjfK,原文链接:https://www.cnblogs.com/DSCL-ing/p/18366199