Liunx笔记
这篇笔记我是在学习Linux过程中的笔记,参考自:
B站韩顺平老师的课程Linux
黑马程序员的《Linux系统管理与自动化运维》教材
第一章 文件目录结构
一、基本介绍
Linux 的文件系统是采用级层式的树状目录结构,在此结构中的最上层是根目录“/ ”,然后在此目录下再创建其他的目录。
记住一句经典的话:在 Linux 世界里,一切皆文件(!!)
linux命令提示符[aaa@localhost ~]$各个符号的含义
[root@localhost ~]#
[]:这是提示符的分隔符号,没有特殊含义。- root:显示的是当前的登录用户,例如我现在使用的是root用户登录。
- @:分隔符号,没有特殊含义。
- localhost:当前系统的简写主机名(完整主机名是 localhost.localdomain)。
- ~:代表用户当前所在的目录,例如当前用户在/opt/abc目录下时,显示为
[root@localhost abc]#,当当前目录为用户的家目录时用~符号表示, - #:命令提示符,Linux 用这个符号标识登录的用户权限等级。如果是超级用户,提示符就是 #;如果是普通用户,提示符就是 $。
家目录就是用户登录时的初始目录。
- 超级用户的家目录:/root。
- 普通用户的家目录:/home/用户名。
用户在自己的家目录中拥有完整权限,所以我们也建议操作实验可以放在家目录中进行。
二、具体的目录结构
-
/bin [常用] (/usr/bin 、 /usr/local/bin)
是 Binary 的缩写, 这个目录存放着最经常使用的命令 -
/sbin (/usr/sbin 、 /usr/local/sbin)
s 就是 Super User 的意思,这里存放的是系统管理员使用的系统管理程序。 -
/home [常用]
存放普通用户的主目录,在 Linux 中每个用户都有一个自己的目录,一般该目录名是以用户的账号命名。
-
/root [常用]
该目录为系统管理员,也称作超级权限者的用户主目录 -
/lib
系统开机所需要最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库
-
/lost+found
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件
- /etc [常用]
所有的系统管理所需要的配置文件和子目录, 比如安装 mysql 数据库 my.conf
-
/usr [常用]
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与 windows 下的 program files 目录。 -
/boot [常用]
存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件
-
/proc [不能动]
这个目录是一个虚拟的目录,它是系统内存的映射,访问这个目录来获取系统信息
-
/srv [不能动]
service 缩写,该目录存放一些服务启动之后需要提取的数据
-
/sys [不能动]
这是 linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs【别动】
-
/tmp
这个目录是用来存放一些临时文件的
-
/dev
类似于 windows 的设备管理器,把所有的硬件用文件的形式存储
-
/media [常用]
linux 系统会自动识别一些设备,例如 U 盘、光驱等等,当识别后,linux 会把识别的设备挂载到这个目录下
- /mnt [常用]
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将外部的存储挂载在/mnt/上,然后进入该目录就可以查看里的内容了。 例如VM的共享文件夹d:/myshare就是放在这个目录下。
-
/opt
这是给主机额外安装软件所存放的目录。如安装 ORACLE 数据库就可放到该目录下。默认为空
-
/usr/local [常用]
这是另一个给主机额外安装软件所安装的目录。一般是通过编译源码方式安装的程序 -
/var [常用]
这个目录中存放着在不断扩充着的东西,习惯将经常被修改的目录放在这个目录下。包括各种日志文件。 -
/selinux [security-enhanced linux]
SELinux 是一种安全子系统,它能控制程序只能访问特定文件, 有三种工作模式,可以自行设置.
第二章 Vi和Vim编辑器
一、vi 和 vim 的基本介绍
Linux 系统会内置 vi 文本编辑器
Vim 具有程序编辑的能力,可以看做是 Vi 的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。
代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用
二、vi 和 vim 常用的三种模式
-
正常模式
以 vim 打开一个档案就直接进入一般模式了(这是默认的模式) 。在这个模式中, 你可以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容, 也可以使用『复制、粘贴』来处理你的文件数据。
-
插入模式
按下 i, I, o, O, a, A, r, R 等任何一个字母之后才会进入编辑模式, 一般来说按 i 即可. -
命令行模式
按 Esc 再输入:在这个模式当中, 可以提供你相关指令,完成读取、存盘、替换、离开 vim 、显示行号等的动作则是在此模式中达成的!
三、各种模式的相互切换

(1)命令模式与插入模式间的切换。
一般情况下,用户可以使用按键 i,直接进入编辑模式,此时内容与光标的位置和命令模 式相同。另外还有其余多种按键,可以不同的形式切换到编辑模式。下面通过表2-47 对其余按键逐一进行讲解。

另使用Esc 键可从插入模式返回命令模式。
(2)命令模式与底行模式间的切换。
在命令模式下使用输入“:”或"/"按键,可进入底行模式。若想从底行模式返回到命令模式,可以使用Esc 键。若底行不为空,可以连按两次 Esc 键,清空底行,并返回命令模式。
四、vi 和 vim 快捷键
- 拷贝当前行 yy , 拷贝当前行向下的 5 行 5yy ,并粘贴(输入 p)。
- 删除当前行 dd , 删除当前行向下的 5 行 5dd
- 在文件中查找某个单词 [命令行下输入 /关键字 , 回车查找 , 再输入 n 就是查找下一个 ,N为查找上一个]
- 设置文件的行号,取消文件的行号.[命令模式下 : set nu 和 :set nonu]
- 定位首行和尾行,在一般模式下, 使用快捷键到该文档的最末行 G 和最首行 gg
- 撤销动作,在一般模式下, 撤销动作为 u
- 定位某行,在一般模式下, 输入 20,再输入 G,则光标移动到20行首
五、vi/vim键盘图

六、三种模式下的操作
1.命令模式
(1)光标移动

(2)复制和粘贴

(3)删除

2、底行模式
(1):set nu: 设置行号,仅对本次操作有效,当重新打开文本时,若需要行号,要重新 设置。
(2):set nonu:取消行号,仅对本次操作有效。
(3):n: 使光标移动到第 n 行。
(4):/xx: 在文件中查找xx,若查找结果不为空,则可以使用n 查找下一个,使用 N 查找上一个。
(5)底行模式下还可以进行内容替换,其操作符和功能如表2-45所示。

(6)操作完毕后,如要保存文件或退出编辑器,可先使用 Esc 键进入底行模式,再使用 表2-46中的按键完成所需操作。

第三章 用户管理
一、关机重启
shutdown # 默认为1分钟后关机
shutdown -h now # 立即重启
shutdown -h 3 # 三分钟后关机
shutdown -r now # 立即重启
reboot # 立即重启
halt # 立即关机
sync # 把内存的数据同步到磁盘
shutdown -c # 阻止关机或重启
# 注意:虽然shutdown/rebot/halt再关机前都已经运行了sync;但最好还是在关机之前执行一下sync。
二、用户登录和注销
su - 用户名 # 切换用户,高级切换到低级不用密码 -后面有空格
logout # 注销用户
logout注销时,退回到上次登录的用户 root->abc->aaa->root->abc
[root@localhost ~]# su - abc
[abc@localhost ~]$ su - aaa
密码:
[aaa@localhost ~]$ su - root
密码:
[root@localhost ~]# su - abc
[abc@localhost ~]$ logout
[root@localhost ~]# logout
[aaa@localhost ~]$ logout
[abc@localhost ~]$ logout
[root@localhost ~]# logout
# 退出系统
三、添加用户(root)
useradd 用户名 # 创建一个用户 只有root用户才有权限创建用户
useradd -d 家目录 用户名 # 给新创建的用户指定家目录
pwd # 显示当前用户所在的 目录
- 当创建用户成功后,会自动的创建和用户同名的家目录,默认为 /home/用户名
- 也可以通过 useradd -d 指定目录 新的用户名,给新创建的用户指定家目录

四、修改密码
passwd # 修改密码 普通用户只能修改自己的密码,若要修改其他普通用户的密码需要使用sudo
passwd 用户名 # 只有root才能指定用户名

五、删除用户(root)
userdel 用户名 # 删除用户,但保留其家目录
userdel -r 用户名 # 删除用户及其家目录
userdel -f 用户名 # 强制删除用户,即便是当前用户
# 一般情况建议保留家目录
六、修改用户
usermod

六、其他
# 当普通用户想要更改其他普通用户的密码时,可以使用sudo passwd 用户名来更改
# 查看已创建的用户
cat /etc/passwd # root用户在第一行,普通用户创建时追加到末尾,中间的用户是给系统使用的。
# 查看用户的密码
cat /etc/shadow # 需要root权限,且看到的密码是加密的
# 查询用户信息
id 用户名
[root@localhost home]# id root
uid=0(root) gid=0(root) 组=0(root)
用户id 组id
# 查看当前登录用户
whoami或who am i
[root@localhost home]# whoami
root
[root@localhost home]# who am i
root pts/1 2023-08-02 16:44 (192.168.178.1)
七、用户组
类似于角色,系统可以对有共性/权限的多个用户进行统一的管理
创建用户时,若不指定组名,则会自动创建一个与用户名同名的组,并将用户加入到这个组,这个组称为基本组。
groupadd 组名 # 新增组
groupdel 组名 # 删除组
useradd -g 用户组 用户名 # 增加用户时直接加上组,前提是组已经存在
usermod -g 用户组 用户名 # 修改用户的组
若在某个用户的目录中创建文件,文件的所属组,就是用户的基本组;另外可以为用户指定附加组,除基本组之外,用户所在的组都是附加组,为用户指定附加组,可以使用户拥有对应组的权限。
用户可以从附属组中移除,但不能从所属组中移除。
# 为用户添加附属组
gpasswd -a aaa abc # 将aaa加入到abc组中
# 从用户组中删除用户
gpasswd -d aaa abc # 将aaa从cbc组中删除
改变用户所在组
root的管理权限可以改变某个用户所在的组。
usermod -g 新组名 用户名 # 改变用户所在组
usermod -d 目录名 用户名 # 改变该用户登陆的初始目录。
# 特别说明:用户需要有进入到新目录的权限。
八、用户和组相关文件
-
/etc/passwd文件
用户(user)的配置文件,记录用户的各种信息
每行的含义:用户名: 口令:用户标识号(uid):组标识号(gid):注释性描述:主目录(用户的家目录):登录 Shell
Shell的作用:对用户输入的指令进行翻译/解释后再交给Linux内核,国内常用的时bashell。
vim /etc/passwd # 可使用vim查看 -
/etc/shadow文件
口令的配置文件
每行的含义:登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
-
/etc/group文件
组(group)的配置文件,记录 Linux 包含的组的信息
每行含义:组名: 口令:组标识号:组内用户列表
九、用户切换
1、su

# 选项
-l #切换用户的同时,切换到对应用户的工作目录,环境变量也随之改变
# 选项为空时默认不切换工作目录和环境变量
su # 不加选项和用户名,默认切换到root用户,但环境变量和工作目录不会改变
su - # 切换到root,环境变量和工作目录会改变
su - abc # 切换到abc用户,并改变环境变量和工作目录

2、sudo
# sudo命令格式:
sudo [选项] -u 用户 [命令]

①sudo命令可以视为受限的su,它可以使“部分”用户使用其它用户的身份执行命令。
②在使用sudo命令之前,需要通过修改/etc/sudoers文件,为当前用户配置要使用的权限。
③/etc/sudoers文件有一定的语法规范,为避免因修改后出现语法错误,应使用visudo命令打开文件进行修改。(visudo命令在保存时可以进行语法检查)
④如下所示为/etc/sudoers]文件中的一条配置信息,该信息设置了root用户可能任何情境下执行任何命令。
root ALL=(ALL) ALL
用root用户编辑sudoers文件,为其他用户提升权限
首先在 root用户下使用 visudo 命令打开 sudoers文件,如下所示:
[root@localhost ~]# visudo
观察 sudoers文件,可以在其中找到如下的语句:

第一条语句是注释行,第二条语句是对 root用户的权限设置,它的作用是:使 root 用 户能够在任何情境下执行任何命令。 sudoers文件中的所有权限设置语句都符合如下格式:
账户名 主机名称=(可切换的身份) 可用的命令
以上格式中包含4个参数,每个参数的含义如下。
账户名:该参数是要设置权限的账号名,只有账号名被写入sudoers文件时,该用户才能使用 sudo 命令。root 用户默认可以使用 sudo命令。
主机名称:该参数决定此条语句中账户名对应的用户可以从哪些网络主机连接当前Linux 主机,root 用户默认可以来自任何一台网络主机。
可切换的身份:该参数决定此条语句中的用户可以在哪些用户身份之间进行切换,执行哪些命令。 root 用户默认可切换为任意用户。
可执行的命令:该参数指定此条语句中的用户可以执行哪些命令。注意,命令的路径应为绝对路径。 root 用户默认可以使用任意命令。
以上语句中的参数 ALL 是一个特殊的关键字,分别代表任何主机、任何身份和任何命令。
以用户aaa为例,若要使用户aaa能以root用户的身份执行/bin/more命令, 则应在sudoers文件中添加如下内容:
aaa ALL=(root) /bin/more
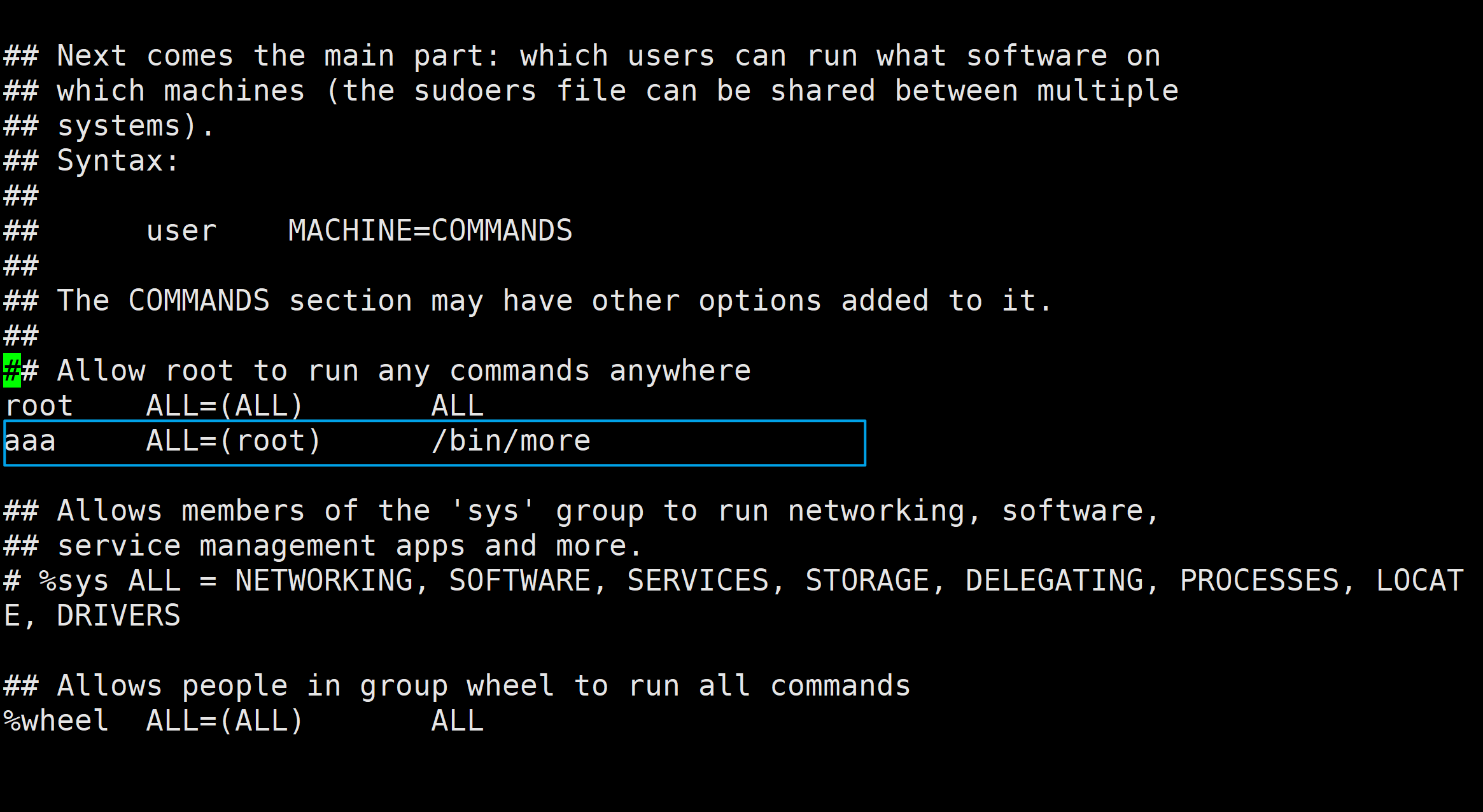
保存退出后,切换到用户aaa,使用命令sudo -l可查看该用户可以使用的命令。

为用户组内的整组用户统一设置权限
在 sudoers 文件中有如下所示的语句:
# %swheel ALL=(ALL) ALL
以上语句中,%声明之后的字符串是一个用户组,该语句表示任何加入用户组 wheel 的用户,都能通过任意主机连接、以任何身份执行全部命令。因此若想提升某些用户的权限 为ALL, 将它们添加到用户组 wheel 中即可。#是注释符,若要是命令生效,需要将#删除。
以用户组aaa为例,若要使该组中的所有用户能以root的身份执行命令/bin/more,则应在sudoers文件中添加如下命令:
aaa ALL=(root) /bin/more
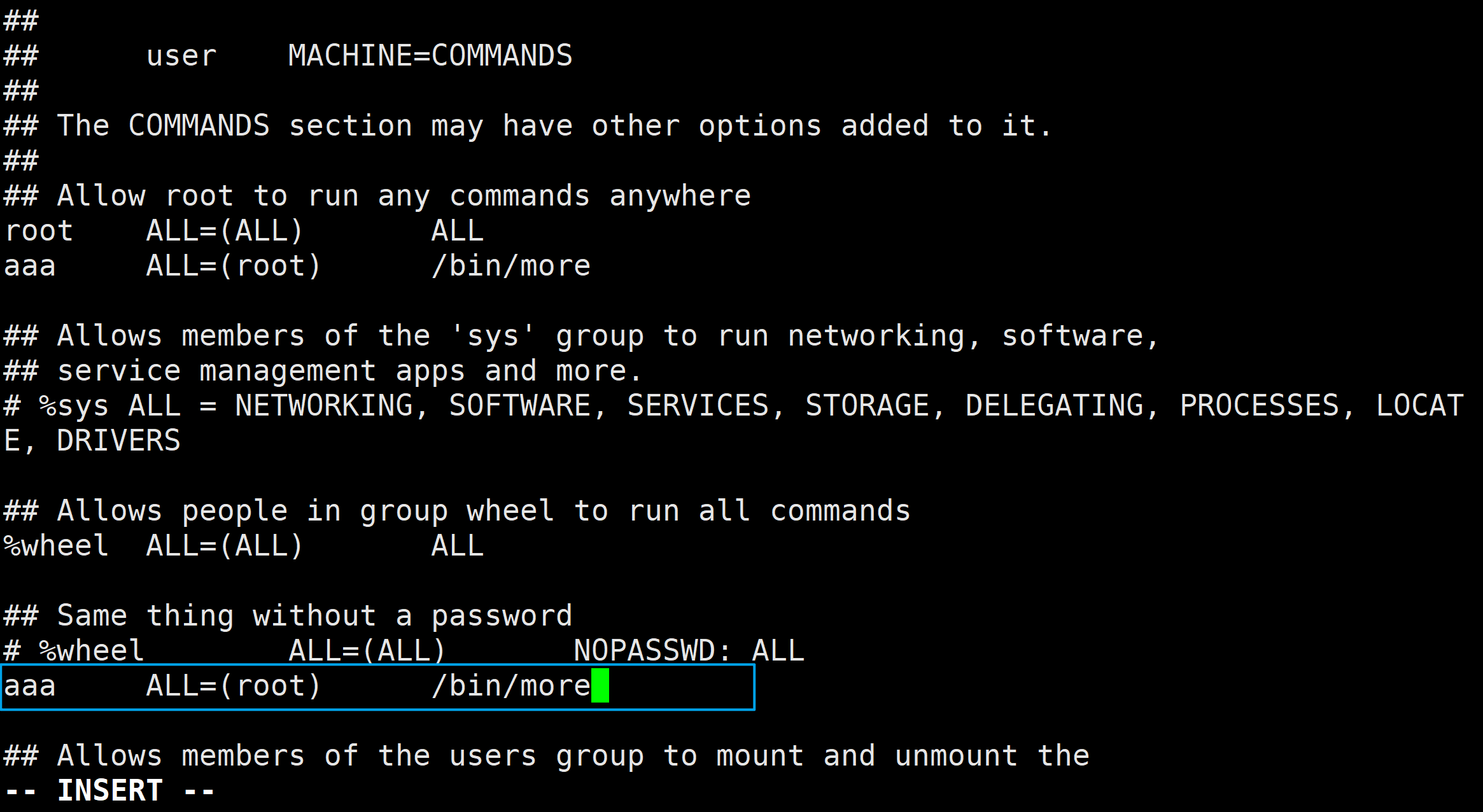
root作为系统中唯一的超级用户,权限极大,可以执行的命令极多,其中不乏非常危险 的命令,如“rm-rf”。 若是一个普通用户的权限被提升的太多,很可能会危及整个系统,为 了防止这种情况,sudo 命令中可以在配置 sudoers文件时,对某些用户的权限进行控制。假 如在 itheima用户被提升至 root权限时,要禁止该用户使用/bin/more 命令,可以使用以下 语句:
aaa ALL=(root) ALL,!/bin/more
以上语句通过!符号禁止用户执行某些命令。ALL,!/bin/more的含义是允许用户使用所有命令,除了/bin/more下的命令不能使用。

注意:若在sudoers文件中将普通户aaa的rmml禁用,那么aaa将不能使用sudo rm命令,但aaa仍然能够直接使用rm命令。
例如,现在我将在sudoers文件中,将aaa的rm命令禁用,然后切换到aaa用户。在aaa用户的家目录下使用touch命令创建一个名为1.txt的文件,然后分别用sudo rm -f 1.txt命令和rm -f 1.txt命令删除1.txt文件。


可以看到,aaa用户无法通过sudo使用rm命令,但能够直接使用rm命令。
第四章 实用指令
Linux命令格式:
command [options] [arguments] # 名称 [选项] [作用对象]
例如:
rm -r abc # 递归的删除abc目录及其子目录
-r为短选项,短选项可以组合使用,如-rf
也可以使用长选项,--recursive 长选项只能单独使用,如rm --recursive --force abc
一、指定运行级别
1、基本介绍
运行级别说明:(不同的centos版本会有所不同?)
0 :关机
1 :单用户【找回丢失密码】
2:多用户状态没有网络服务
3:多用户状态有网络服务
4:系统未使用保留给用户
5:图形界面
6:系统重启
常用运行级别是 3 和 5
init 0123456 # 切换运行级别
2、更改默认运行级别
CentOS7 后运行级别说明
在 centos7 以前, /etc/inittab 文件中 .
进行了简化 ,如下:
multi-user.target: analogous to runlevel 3
graphical.target: analogous to runlevel 5
systemctl get-default # 查看当前默认运行级别
systemctl set-default multi-user.target # 默认运行级别切换为3
systemctl set-default graphical.target # 默认运行级别切换为5
# 也可以使用已下命令更改运行级别
systemctl set-default runlevel 运行级别(数字)
二、找回root密码
-
刚开机时再这个界面按e,进入编辑界面

文件的硬连接数为1,空目录的硬链接数为2,当目录下每新增加一个目录时,该目录的硬链接数+1。
(3)cd 切换到指定目录
cd命令的原意为change directory,即更改目录。
用法:cd [参数] cd ~或cd # 回到用户的家目录;如root则回到/root。abc则回到/home/abc cd .. # 回到当前目录的上一级目录,最多退回到/根目录 没有cd ... # 若当前在/home目录下 cd aaa # 使用相对路径,前往/home/aaa # 若当前在/home/aaa目录下 cd ../../root # 使用相对路径,前往root2、创建和删除
(1)mkdir 创建目录
用法:mkdir [选项] 要创建的目录 mkdir /home/one # 创建一个目录one mkdir -p /home/two/three # 创建多级目录two/three(2)rmdir 删除空目录
用法:rmdir [选项] 要删除的空目录 rmdir home/one # 删除空目录one,有隐藏文件也不行 rm -rf home/two # 强制删除目录two,不管是否为空 # 注意:rmdir与rm是不同的,可以用man查看(3)rm 删除目录或文件
用法:rm [选项] 要删除的目录或文件 选项:-r 递归的删除目录(没有-r的话只能删除文件) -f 删除时不提示,(rm删除时默认都是提示的)(4)touch 创建空文件
用法:touch 文件名或目录/文件名 touch hello.txt # 创建hello.txt文件 touch /home/lll/hello # 在/home/lll下创建空文件hello3、拷贝移动
(1)cp 拷贝文件到指定目录
用法:cp [选项] suorce(要拷贝的文件或目录) dest(要拷贝到的目录) 选项:-r 递归的复制整个文件夹 \cp /home/bbb/hello.txt /home/ccc/ # 在cp前加上\默认覆盖同名文件或文件夹(2)mv 移动文件、目录或重命名
用法:mv [选项] 要移动的目录或文件 移动到的目录 mv oldNameFile newNameFile # 重命名 (在同一目录) mv /home/bbb/hello.txt /home/hello66.txt # 移动并且重命名文件 mv /home/bbb /home/ddd/bbb123 # 移动且重命名目录 (注意:若ddd中已经有名为bbb123的目录,则会将bbb移动到bbb123/下,不会重命名4、查看
(1)cat 查看文件
用法:cat [选项] 要查看的文件 选项:-n 显示行号 cat -n /etc/profile | more # 使用管道命令,查看更方便。more类似于分页的作用;按回车显示下一行,空格显示下一页 管道命令:将|前的命令得到的结果交给|后面的命令进行处理(2)more 查看文件(可交互)
more 指令是一个基于 VI 编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more 指令中内置了若干快捷键(交互的指令)
用法:mmore 要查看的文件名
(3)less 分屏查看文件内容
less 指令用来分屏查看文件内容,它的功能与 more 指令类似,但是比 more 指令更加强大,支持各种显示终端。less 指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
用法:less 要查看的文件
(4)head 查看文件开头内容
用法:head [选项] 文件 head /opt/123.txt # 默认显示前10行 head -n 20 /opt/123.txt # 显示前20行(5)tail 显示文件末尾的内容
用法:tail [选项] 文件 选项:-n 行数 指定显示的行数 -f 输出末尾10行,并持续监控文档的更新。按Ctrl+C退出 tail /opt/123.txt # 默认显示末尾10行 tail -n 3 /opt/123.txt # 显示末尾3行 tail -f /opt/123.txt # 监控文档更新(6)wc 统计文件的字节数、字数、和列数
wc [选项] 参数 # 选项 -c 统计字节数 -l 统计行数 -w 统计字数# 用法: wc -c /etc/passwd # 统计passwd文件的字节数 wc -l /etc/passwd # 统计passwd文件的行数 wc -w /etc/passwd # 统计passwd文件的字数5、其他
(1)echo 输出内容到控制台
用法:echo 输出的内容 echo $HOSTNAME # 输出主机名 echo $PATH # 输出环境变量 echo 'hello world' # 输出字符串(2)'>' 输出重定向和>>追加
用法:内容 >或>> 文件 # 若文件不存在则会自动创建文件 ls -l > /home/mydate.txt # 将ls -l 输出的列表写入文件mydate.txt内 cat >> /home/mydate.txt # 将cat输出的日历写入到mydate.txt中 cat 文件1 > 文件2 # 将文件1的内容全部写入文件2内,相当于复制了一份 echo '我来啦' > 文件 # 将’我来啦‘写入文件 注意:>为重定向,会将文件内所有内容替换为写入的内容, >>为追加,在文件末尾追加写入内容(3)ln 软链接
也叫做符号链接,类似于Windows下的快捷方式;主要存放了链接到其他文件的路径。
用法:ln -s [原文件或目录] [软链接的名称] ln -s /root/ /home/myroot # 在home下创建链接/root目录的软链接 rm /home/myroot # 删除myroot。注意:这里myroot后不要有/,不然删除的就是root目录 注意:从软链接进入到链接的目录时,用pwd查看后的目录仍时软链接所在的目录。如pwd后显示/home/myuroot/桌面(4)history 查看已经执行过的历史指令,或执行历史指令
用法:history # 查看已经执行过的历史指令 history 10 # 查看最近执行过的10条指令 !123 # 执行历史编号为123的指令 。。。连续执行相同的一条指令,好像只算作一条。五、时间日期类
1、date 显示当前日期/设置日期
显示当前日期
date # 显示当前时间 date +%Y # 显示当前年份 date +%m # 显示当前月份 date "+%Y-%m-%d %H:%M:%S" # 自定义显示的时间格式,%后的字母依次表示为,年月日时分秒。设置系统当前日期
date -s "字符串时间" date -s "2023-08-23 14:40:30" # 这里的格式只能是这种,年-月-日 时:分:秒 怎么恢复???重启吗2、cal 显示日历
用法:cal [选项] 参数 cal # 显示当月日历 cal 2023 # 显示2023年的日历六、查找类
1、find 查找文件
从指定目录向下递归的遍历整个子目录,并将满足条件的文件或目录显示在终端。
选项说明:
-name<查询方式> 按照指定的文件名查找模式,查找文件
-user<用户名> 查找属于指定用户名的文件
-size<文件大小> 按照指定文件大小查找文件
用法:find 查找范围 [选项] find /home -name hello.txt # 在home目录下查找文件名为hello.txt的文件 find /etc/ -user abc # 在etc下查找属于用户abc的文件 find / -size +200M # 在根目录下查找大于200M的文件(-小于,+大于,默认等于;单位K,M,G)2、locate 快速搜索文件
locate指令可以快速定位文件路径。
locate指令利用事先建立的系统中所有文件名称及路径的locate数据库实现快速定位给定的文件。Locate指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新locate时刻。
locate指令基于数据库进行查询,所以第一次运行前,必须使用updatedb指令创建locate数据库
updatedb locate hello.txt # 它应该是匹配文件名字符串,若使用locate a.txt 则123llla.txt这个文件路径也会输出到终端3、which 查看某个指令所在的目录
用法:which 指令 which ls4、grep查找文件中的内容
grep过滤查找,可以与管道符“|”连用。输出查找内容所在的那一行
用法:grep [选项] 查找内容 文件 选项:-n 显示行号 -i 不区分字母大小写 使用形式如下: cat /home/hello.txt | grep -n lll # 查找/home/hello.txt文件中的lll字符 grep -ni liu /home/hello.txt # 查找/home/hello.txt文件中的liu字符,不区分大小写 cat -n hello.txt | grep lll # 也会显示行号七、压缩和解压
1、gzip/gumzip 压缩解压文件
不能压缩目录,只能解压或压缩为.gz文件
压缩之后,这个文件就变成了压缩文件,解压时也类似。解压或压缩后,源文件不保留。
用法:gzip 文件 # 压缩文件,只能将文件压缩为*.gz文件 gunzip XXX.gz # 解压.gz文件2、zip/unzip 压缩解压文件或目录
zip压缩解压时默认会保留原文件。压缩目录时若不使用-r选项,则只会压缩到那个空文件夹,不会压缩其下面的文件或文件夹。
用法:zip [选项] 压缩后的文件名.zip 要压缩的文件或文件夹 # 压缩 unzip XXX.zip # 解压 选项:zip -r 递归压缩,(压缩目录) unzip -d 目录 解压到指定的命令 zip hello.zip /home/hello.txt # 将hello.txt压缩为hello.zip.默认保存在当前目录下 unzip -d /home/hello /home/hello.zip 将hello.zip解压到hello目录下 zip -r bbb.zip /home/bbb/ # 将bbb及其下面的文件压缩为bbb.zip unzip bbb.zip # 将bbb.zip解压到当前目录。文件名为bbb3、tar 打包文件或目录
-
-z或--gzip或--ungzip 通过gzip指令处理备份文件
-
-c 建立新的备份(打包)文件
-
-v 显示指令执行过程。
-
-x 从备份文件中还原文件。
-
-f<备份文件> 指定备份文件。
-
-C<目的目录> 切换到指定的目录。
注意:选项z一定要放在f的前面
tar -zcvf 压缩后的文件名.tar.gz 文件夹1 文件夹2 文件1 文件2 # 将多个文件、文件夹打包压缩为tar.gz文件 tar -zcvf myhome.tar.gz /home # 将home文件夹及其子文件(夹)打包压缩为myhome.tar.gz文件 tar -zxvf myhome.tzr.gz # 将myhome.tzr.gz解压到当前文件夹 tar -zxvf myhome.tzr.gz -C /home/hello/ # 将myhome.tzr.gz解压到/home/hello文件夹下八、权限管理
几种权限的解释
根据用户与文件的关系,Linux 系统中的用户分为:文件或目录的拥有者、同组用户、其他组用户和全部用户;
又根据用户对文件的权限,将用户权限分为:读取权限(read)、写入权限(write)和执行权限(execute)。
权 限 对应字符 对应数值 文 件 目 录 读权限 r 4 可读取、查看文件内容 可以读取、列出目录中的内容 写权限 w 2 可修改文件内容(但不能删除文件) 可以在目录中创建、删除、重命名文件 执行权限 x 1 可执行该文件 可以进入目录 当对某个问价有写权限时,并不代表可以删除该文件。删除一个文件的前提是对该文件所在的目录有写权限,才能删除这个目录下的文件。
权限对应的数字为什么是4、2、1?
因为只读时字母表示为r--,如果把有权限用1,没权限用0表示,则r--可以表示为100,二进制的100对应十进制的4;同理,-w-等价于010,十进制为2;--x等价于001,十进制为1。
组合使用:例如5=4+1,表示有读和执行的权限。3=2+1表示有写和执行的权限。
查看文件或目录的权限
ls -l命令可以查看文件的详细信息,例如可以使用ls -l file命令查看文件file的详细信息:[liu@iZ2vc0k1wlrps7orfwgkqaZ ~]$ ls -l file -rw-rw-r-- 1 liu liu 0 Oct 24 20:16 fileLinux系统中任何文件的属性信息都与以上信息的格式相同。属性信息由空格分隔, 其中第一个字段"-rw-rw-r-"包含10个字符,下面是对这10个字符的说明:
(1)第0位确定文件类型(d,-,l,c,b)
- -表示普通文件
- l是链接,相当于windows的快捷方式。
- d是目录,相当于windows的文件夹。
- c是字符设备文件,如鼠标、键盘
- b是块设备,比如硬盘
(2)第1-3位确定所有者(该文件的所有者)拥有该文件的权限。-User
(3)第4-6位确定所属组(同用户组的用户)拥有该文件的权限,-Group
(5)第7-9位确定其他用户拥有该文件的权限--Other如上面file文件的"rw-","rw-","r--"3,分别表示文件所有者权限、同组用户权限和其他用户权限;rwx分别对应读、写和执行权限,若对应权限为“- ”,则表示用户没有此项权限。
示例:-rw-rw-r-- 第一个字符:-,说明该文件是普通文件 第1-3个字符:rw-,表示文件的拥有者有读、写权限,没有执行权限 第4-6个字符:rw-,表示文件拥有者的同组用户有读、写权限,没有执行权限 第7-9个字符:r--,表示其他用户只有读的权限。常用的权限管理命令有 chmod、chown、chgrp等,默认情况下,普通用户不能使用权限管理命令,下面分别对这3个权限管理命令进行讲解。
1、chmod
chmod 命令的原意为 change the permissions mode of file,其功能为变更文件或目录的权限,该命令的格式如下:
chmod [选项] [{augo}{+-=}] [文件或目录]以上格式中,各字母及符号的含义如下:
字母 含义 符号 含义 a 即all,表示所有用户 + 添加权限 u 即user,表示用户名user - 取消权限 g 即group,表示组名group = 设定权限 o 即other,表示其他用户或其他用户组 chmod命令常用选项:
选项 说 明 -f 不显示错误信息 -V 显示指令执行过程 -R 递归处理,处理指定目录及其中所有文件与子目录 示例:
# 为目录dir添加权限,使目录所有者和同组用户都拥有执行权限 [rootelocalhost~]# chmod u+x,g+x dir也可以使用数值形式表示权限:
# 使用数值形式将目录bxg的权限设置为rwxr-xr-- [root@localhost ~]# chmod 754 bxg # 000等价于---------2、chown
chown 命令的原意为 change the owner of file,其功能为更改文件或目录的所有者。
默认情况下文件的所有者为创建该文件的用户,或在文件被创建时通过命令指定的用户,但在需要时,可使用 chown 对文件的所有者进行修改。该命令的格式如下:
chown [选项] [用户] [文件或目录]常用选项:
选项 说 明 -f 不显示错误信息 -V 显示指令执行过程 -R 递归处理,处理指定目录及其中所有文件与子目录 示例:
# 更改目录bxg的所有者为itheima [root@localhost ~]# chown itheima bxg3、chgrp
chgrp命令的原意为 change file group,用于更改文件或目录的所属组。
一般情况下,文件或目录与创建该文件的用户属于同一组,或在被创建时通过选项指定所属组,但在需要时,可通过chgrp命令更改文件的所属组。 chgrp命令的格式如下:
chgrp 组名 文件或目录示例:
# 修改目录bxg的所属组为itheima [rootelocalhost~]# chgrp itheima bxg权限管理练习(完成)


九、存储管理
一块新的磁盘无法直接使用,无论是 Windows 系统还是 Linux 系统,若要使用新添加 的磁盘,都需先对磁盘进行分区。
常见的磁盘分区有两种,分别为MBR分区和GPT分区。
1、MBR分区
早期磁盘采用MBR 方式进行分区。 MBR 全称 Master Boot Record,即主引导记录。 磁盘中的空间以扇区为单位,采用MBR 方式分区的磁盘第一个扇区中包含一个64B 的磁盘分区表,每个分区信息占用16B,因此分区表最多可存储4项分区信息,也就是说,磁盘只能划分出4个主分区。即便4个分区容量总和小于磁盘总容量,也无法再为剩余空间分区。

MBR允许在基础分区中设置一个扩展分区,而扩展分区又可以划分为多个逻辑分区。

在 MBR 分区中,编号1~4被预留给基础分区,所以逻辑分区的编号一定从5开始(即便基础分区数量不足4个)。扩展分区也有自己的磁盘分区表,扩展分区的磁盘分区表存储于扩展分区的第一个扇区中。
使用MBR 方式创建的分区,可通过 fdisk 命令进行管理。
fdisk 命令
fdisk命令可以查看当前系统中磁盘的分区情况,该命令的格式如下:
fdisk [选项] [磁盘]选项 说 明 -l 详细显示磁盘及其分区信息 -s 显示磁盘分区容量(单位为block) -b 设置扇区大小(扇区大小取值为512、1024、2048或4096,单位为MB) fdisk命令的用法示例如下:
# 打印磁盘/dev/sda的详细信息 [root@localhost ~]# fdisk -l /dev/sda # 显示磁盘分区容量 [root@localhost~]# fdisk -s /dev/sda # 设置磁盘/dev/sda的扇区大小 [root@localhost ~]# fdisk -b 512 /dev/sda以上操作只能实现磁盘与分区的简单管理,若要使用fdisk命令创建磁盘分区,需要在 终端输入
fdisk 磁盘命令进入fdisk的交互界面。在终端输入fdisk 磁盘,将会进入如下所示的界面:
注意:fdisk的交互界面所做的配置并不会立即生效,而是要使用输入w,保存并退出后,配置才会生效。若只是做练习,可以在配置完成后,输入q,退出不保存。
输入m查看帮助信息:

常用的字母:
fdisk命令的使用方法
使用
fdisk -l /dev/sda命令查看/dev/sda目前的分区情况。
由上图可知,/dev/sda共有41943040个扇区,目前已有两个主分区,两个主分区共占用41943039个扇区,也就是两个分区将磁盘占满了。
通常情况下,我们都是在交互界面对硬盘进行分区配置。为了方便理解,下面直接来个案例,讲述fdisk交互界面中的用法。
案例:添加一块新硬盘
(1)在VMware软件中为虚拟机添加硬盘
如下图,点击下一步后,除硬盘大小之外,所有选项都保持默认即可。添加完成后,需重启虚拟机,新添加的硬盘才会生效。

(2)在虚拟机中使用
lsblk命令查看磁盘分区情况,可以看到,新加的硬盘为sdb,大小20G。

(3)使用fdisk命令给新加的硬盘分区
fdisk /dev/sdb # 进入交互界面a.添加主分区
输入n添加分区,选项p为添加主分区,e为添加扩展分区。
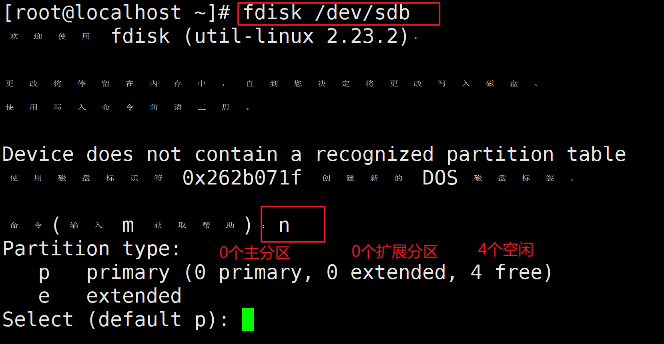
输入p添加主分区,分区号设置为1,起始扇区直接回车,使用默认的2048,Last扇区可以使用+size{K,M,G}的方式,设置分区的大小,这里将分区1大小设置为10G。

b.添加扩展分区
再次输入n添加分区,e添加扩展分区,分区号位2,起始扇区默认,Last扇区+8G。
此时添加了8G的扩展分区。
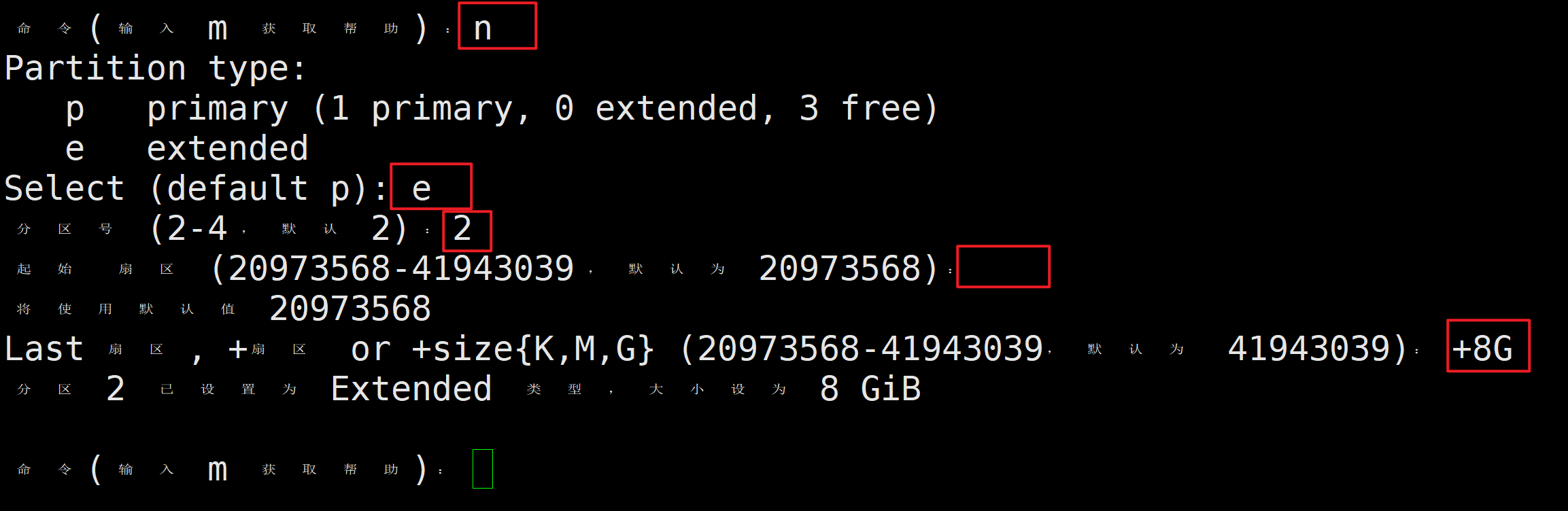
输入p可以打印分区表,
可以看到刚才创建的主分区sdb1和扩展分区sdb2

c.添加逻辑分区
输入n后,输入l添加逻辑分区,逻辑分区的编号从5开始。
添加一个2G的逻辑分区

再添加一个1G的逻辑分区

输入p打印分区表

d.保存退出并查看分区情况
输入w保存并退出,只退出不保存可以输入q,不保存的话刚才的配置不会生效。
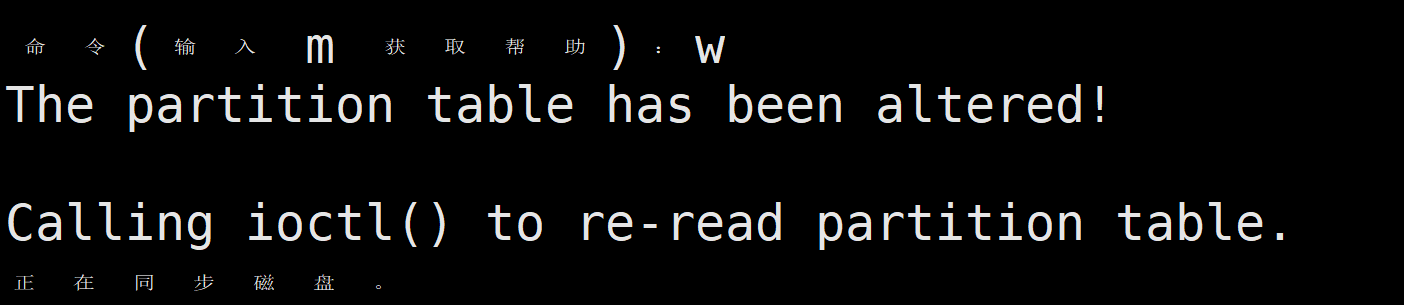
使用
fidesk -l /dev/sdb查看磁盘/dev/sdb的分区:
来自AI的解释:
根据上面输出的信息,我们可以对每个分区进行如下解释:
- /dev/sdb1:这是一个主分区,它的起始扇区是2048,结束扇区是20973567,占用了10485760个扇区,也就是5GB的容量。文件系统类型为Linux。
- /dev/sdb2:这是一个扩展分区,它的起始扇区是20973568,结束扇区是37750783,占用了16777216个扇区,也就是8GB的容量。这个分区是用来划分多个逻辑分区的,不能直接存储文件。它的分区类型是 extended。
- /dev/sdb5:这是第一个扩展分区中的一个逻辑分区。它的起始扇区是20975616,结束扇区是25169919,占用了2097152个扇区,也就是1GB的容量。文件系统类型为Linux。
- /dev/sdb6:这是第一个扩展分区中的另一个逻辑分区。它的起始扇区是25171968,结束扇区是27269119,占用了1048576个扇区,也就是512MB的容量。文件系统类型为Linux。
扇区大小为512字节,这些信息可以帮助我们计算每个分区的占用空间和容量。同时,我们也可以知道每个分区的类型和存储文件系统的信息。
分区信息每一列标题的含义
- 设备: 磁盘设备名,如 /dev/sda、/dev/sdb 等。
- Boot: 是否为启动分区的标识。如果该分区被设置为启动分区,则该列显示一个星号(*),否则为空。
- Start: 分区的起始扇区号,即从哪个扇区开始存储该分区的数据。
- End: 分区的结束扇区号,即到哪个扇区为止存储该分区的数据。
- Blocks: 分区占用的块数,每个块大小为 1KB。
- Id: 分区类型标识符。不同的标识符代表不同的分区类型,如 83 代表 Linux 文件系统分区,82 代表 Linux swap 分区等。
- System: 分区文件系统类型。例如,Linux 分区的文件系统类型可以是 ext4、ext3 等。如果该分区是交换分区,则系统列会显示 “Linux swap / Solaris”。
扇区是什么?
扇区是硬盘等存储介质被划分成的最小存储单位,每个扇区存储一定大小的数据。在硬盘中,每个扇区的大小通常为512字节。操作系统通过扇区号和偏移量来访问硬盘中的数据。例如,如果操作系统要读取硬盘中的某个文件,它会根据文件的起始位置和大小来计算需要读取的扇区号和扇区数量,然后将这些扇区中的数据读取到内存中进行处理。
扇区与Blooks的区别
在分区信息中,"Blocks" 和 "扇区" 都是占用的空间大小的量度单位,但它们所表示的大小不同。在大多数情况下,"扇区" 表示的是物理磁盘的存储单位,而 "块" 则表示的是文件系统的存储单位。
在文件系统中,有一个抽象的概念叫做 "块",它是文件系统管理文件时所使用的最小单位。不同的文件系统块大小不同,例如 Linux ext2/ext3/ext4 文件系统的块大小可以是 1KB、2KB 或 4KB。因此,当我们创建一个新的分区时,需要指定该分区的块数。
2、GPT分区
GPT(GUID Partition Table,全局唯一标识分区表)是一种较新的分区方式,这种分区方式克服了MBR 的很多缺点,它支持超过2TB 的磁盘,向后兼容 MBR。 在 Windows 7 Windows8 系统下若想使用GPT 方式为数据盘分区,可直接进行转换,但若想使用 GPT 方式为系统盘分区,则必须采用支持 UEFI 的主板。此外,GPT 只支持64位操作系统。
可使用parted命令创建GPT分区,其命令格式如下:
parted [选项]设备[命令]下面是parted在命令行模式下常用的功能与相关命令的讲解。
(1)修改分区表类型
使用 parted工具的mklabel命令可以修改磁盘分区表格式,语法格式如下:
parted 磁盘 mklabel gpt由于执行此操作后,磁盘的数据将会丢失,系统会给出警告,用户在输入确认信息后才 会完成更改。
(2)查看分区表信息
使用parted工具的 print命令可以查看磁盘的分区表信息,语法格式如下:
parted 磁盘 print(3)创建分区
使用 parted工具的mkpart 命令可以创建分区,语法格式如下:
parted 磁盘 mkpart 分区类型 文件系统 起始 结束以上格式中的分区类型可以是 primary、logical 或者 extended;文件类型可以是 fat16、 fat32、ext2、linux-swap、reiserfs等。命令中的“起始”和“结束”两个参数用于设置分区的大小,默认单位为MB。
下面以设备/dev/sdc为例,展示使用 parted工具的 mkpart 命令创建分区的方式,具体 示例如下:
# 在/dev/sdc上创建起始位置为1MB,容量为2GB,文件类型为ext2的主分区 parted /dev/sdc mkpart ext2 1 2G(4)删除分区
使用 parted 的 rm 命令可以删除分区,语法格式如下:
parted 磁盘 rm 分区编号下面以设备/dev/sdc为例,展示使用 parted工具的 rm 命令删除分区的方式,具体示例 如下:
# 删除磁盘/dev/sdc 的第2个分区 parted /dev/sdc rm 2(5)分区复制
使用 parted 工具的cp 命令可将一个设备上的指定分区复制到当前设备的指定分区, 语法格式如下:
parted 磁盘 cp 源设备 源分区 目标分区下面以设备/dev/sdc为例,展示使用 parted 工具的 cp 命令复制分区的方式,具体示例 如下:
#将设备/dev/sdb上的分区 sdb3复制到/dev/sdc设备的分区sdc1 parted /dev/sdc cp /dev/sdb sdb3 sdc1除以上操作外,parted 命令还可实现分区检测、分区命名、调整分区大小等操作,读者可参考 Linux 系统的 man 文档自行学习。
3、格式化
磁盘给待存储的数据以硬件支持,但磁盘本身并不规定文件的存储方式,因此在使用磁盘之前,还需规定文件在磁盘中的组织方式,即格式化磁盘,为磁盘创建文件系统。
使用mkfs命令实现格式化分区的功能,命令格式如下:
mkfs [选项] [参数] 分区mkfs 命令常用的选项为-t,该选项用于设置文件系统,若不指定文件系统,则分区默认被格式化为 ext4。
mkfs 命令的用法示例如下:
# 将扩展分区/dev/sda5 格式化,设置其文件系统为ext2 mkfs -t ext2 /dev/sda5也可使用“mkfs.文件系统”的方式格式化分区,示例如下:
# 将扩展分区/dev/sda5 格式化,设置其文件系统为ext2 mkfs.ext2 /dev/sda5Linux 系统在进行分区时,往往会设置一个交换分区。当系统运行程序过多而导致系统效率下降时,会把内存中的一些长时间不用的程序交换出来,以提高运行效率,这些被换 出的程序就存储在交换分区中,如果对交换分区进行格式化,则需要单独使用
mkswap命令格式化。以交换分区/dev/sda6 为例,格式化方式如下:mkswap /dev/sda64、挂载
在Windows 系统中,磁盘分区后便可直接使用,但 Linux 系统的磁盘不但需要进行分区、格式化操作,还需要经过挂载,才能被使用。
所谓挂载,是指将一个目录作为入口,把磁盘分区中的数据放置在以该目录为根节点的目录关系树中,这相当于将文件系统与磁盘进行了链接,指定了某个分区中文件系统访问的位置。 Linux 系统中根目录是整个磁盘访问的基点,因此根目录必须要挂载到某个分区。
Linux 系统中通过mount 命令和 unmount 命令实现分区的挂载和卸载。
(1)挂载
Linux 系统中可以使用
mount命令将某个分区挂载到目录,mount 命令常用的格式如下:mount [选项] [参数] 设备 挂载点mount 命令常用的选项有两个,分别为-t 和-o。 下面分别介绍这两个选项的功能,
选项-t用于指定待挂载设备的文件系统类型,常见的类型如下:
-
ISO9660:光盘/光盘镜像。
-
MS-DOS:DOS fat16 文件系统。
-
VFAT:Windows 9x fat32文件系统。
-
NTFS:Windows NT ntfs 文件系统。
-
SMBFS:Mount Windows 文件网络共享。
-
NFS:UNIX(Linux) 文件网络共享。
Linux 能支持待挂载设备中的文件系统类型时,该设备才能被成功挂载到 Linux 系统中并被识别。
选项-o 主要用来描述设备的挂载方式,常用的挂载方式如表2-26所示。
表2-26 常用的挂载方式
方 式 说 明 loop 将一个文件视为硬盘分区挂载到系统 ro read-only,采用只读的方式挂载设备(即系统只能对设备进行读操作) rw 采用读写的方式挂载设备 iocharset 指定访问文件系统所用的字符集 remount 重新挂载 mount 的参数通常为设备文件名与挂载点。设备文件名即为要挂载的文件系统对应的设备名;挂载点指挂载点目录,设备必须被挂载到一个已经存在的目录上,其中的内容能通过目录访问,挂载的目录可以不为空,但将某个设备挂载到该目录后,目录中之前存放的内容不可再用。
下面以硬盘与镜像文件的挂载为例,来讲解 mount 命令的使用方法。
a、挂载移动硬盘
移动硬盘是一个硬件设备,在挂载之前,需要先将该设备连接到主机。为了确定新连接的设备在系统中的文件名,应先使用"fdisk-1"命令了解当前系统中的磁盘以及分区情况, 之后连接移动硬盘,再次执行"fdisk-1"命令,通过对比,获得新连接设备的名称与分布情况。此时才可以使用mount 命令挂载硬盘或其某个分区到指定目录下。需要注意的是,指定的目录必须已经存在。
假设新添设备的设备名为/dev/sdb, 其中的逻辑分区为/dev/sdb5, 要将该逻辑分区挂载到/mnt/dirl, 则需使用如下命令:
mount /dev/sdb5 /mnt/dir1 mount /dev/sdb /mnt/dir1 # 也可以直接将磁盘sdb挂载到dir1以上命令省略了待挂载设备的文件类型,系统将会自动识别该设备的文件类型。 U 盘挂载的方式与移动硬盘大同小异,读者可参考移动硬盘的挂载方式自行实践。
b、挂载镜像文件(暂时不需要掌握)
镜像文件类似文件压缩包,但它无法直接使用,需先利用虚拟光驱工具将其解压。镜像 文件可以视为光盘的“提取物”,它也可以挂载到 Linux 系统中使用。
假如在/usr 目录下有一个名为test.iso的镜像文件,要求以读写的方式从源目录/usr/ test.iso 挂载到目标目录/home/itheima, 则需使用如下命令:
mount -o rw -t iso9660 /usr/test.iso /home/itheima永久挂载
注意:直接使用mount命令将磁盘挂载到目录下,这样这种方法是临时的,重启之后挂载关系就会被解除,需要重新挂载才能继续使用磁盘。
要实现永久挂载需要修改/etc/fstab文件.
vim /etc/fstab如下图,将需要永久挂载的分区添加到文件中。然后保存退出。

添加完成后输入
mount -a即刻生效。重启系统后,就会发现分区已经自动挂载上了。(2)卸载
当需要挂载的分区只是一个移动存储设备(如移动硬盘)时,要进行的工作是在该设备与主机之间进行文件传输,那么在文件传输完毕之后,需要卸载该分区。 Linux 系统中卸载 分区的命令是
umount, 该命令的格式如下:umount [选项] 参数umount 命令的参数通常为设备名与挂载点,即它可以通过设备名或挂载点来卸载分区。若以挂载点为参数,假设挂载点目录为/mnt, 则使用的命令如下:
umount /mnt通常以挂载点为参数卸载分区,因为以设备为参数时,可能会因设备正忙或无法响应, 导致卸载失败。也可以为命令添加选项-l,该选项代表 lazy mount。 使用该选项时,系统会 立刻从文件层次结构中卸载指定的设备,但在空闲时才清除文件系统的所有引用。
GPT分区练习
使用
lsblk命令查看所有磁盘及其分区情况
第一种,使用非交互时parted分区命令
1、创建GPT分区表
使用下面的命令修改磁盘分区表格式
parted /dev/sdb mklabel gpt # sdb是要分区的磁盘 # mklabel是分区命令 # gpt是分区表格式
2、查看分区表信息
这个命令在后面会多次用到
parted /dev/sdb print # print也可以简写为p
3、创建分区
创建一个名称为name_1,大小为3G的分区
parted /dev/sdb mkpart name_1 0G 3G # mkpart是创建分区的命令 # name_1是分区名字 # 0G和3G分别是起始位置和结束位置,可根据需要自行选择。
再创建两个分区

4、修改分区名称
parted /dev/sdb name 1 part1 # name为修改分区名称的命令 # 1为需要修改的分区的编号 # part1是修改后的名字
再把第三个分区的名称改为part3

4、配置分区的标记
parted /dev/sdb set 1 lvm # set为配置分区标记的命令 # 2为需要配置的分区的编号 # lvm为分区标记
取消分区标记
取消标记的命令与配置的命令一样,只不过取消时,需要输入的是off。

5、删除分区
parted /dev/sdb rm 1 # rm是删除分区的命令 # 1是要删除的分区的编号
6、更改默认显示单位
这个更改只是一时的,就是说使用
parted /dev/sdb unit GB print命令查看时是以GB为单位来显示,但当直接使用parted /dev/sdb print命令查看时还是按照原来的默认显示。parted /dev/sdb unit GB print # unit是更改显示单位的命令 # GB是更改后以GB为单位显示(可以是GB、MB、KB等,不区分大小写)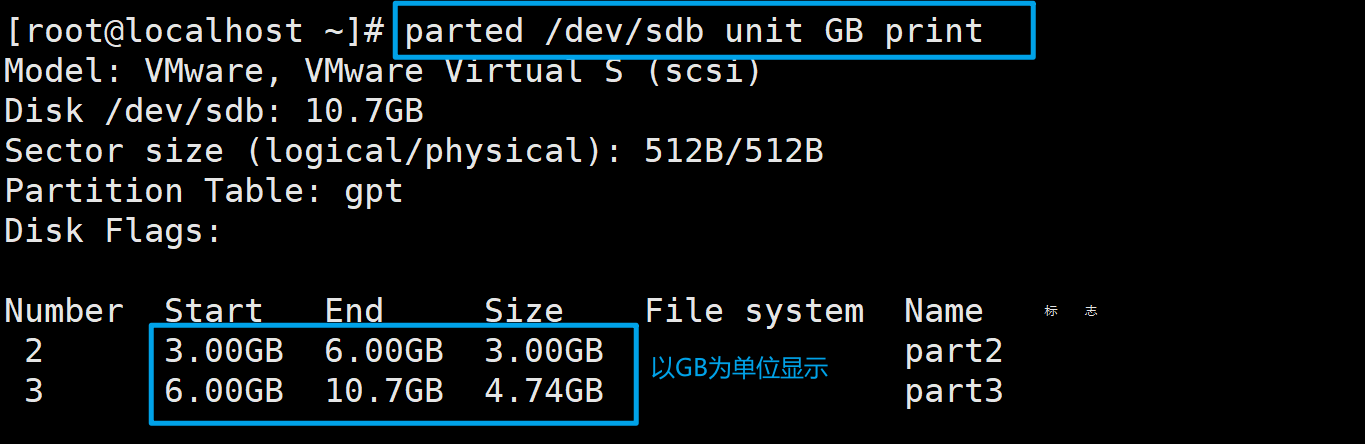


7、怎么计算磁盘剩余容量
使用下面的命令查看磁盘分区情况
parted /dev/sdb print
以上图为例,分区2和3占用了大概7.7G左右的空间,磁盘总容量为10.7G,所以磁盘剩余容量为10.7-7.7=3G。
但是,实际能够利用的空间可能没有3GB。在我这个例子中,3000MB到10.7GB的位置是被分区2和3所占有的,剩余的空间是在1048kB到2999MB之间,这段空间是连续的,所以我能够全部利用。
但如果分区2和3之间不是连续的,比如它们之间相隔着1GB的空间没有被分区,在分区2之前也有1GB的空间没有被分区,分区3之后也有1GB的空间没有被分区。空闲容量同样是3GB,但是这3GB我只能将它们分成3个分区使用,每一个分区只能使用1GB。因为一个分区中的空间必须是连续的(除非使用LVM)。
第二种,使用交互模式来进行分区管理
在命令行中输入下面的命令进入到交互模式
parted /dev/sdb # sdb是需要配置的磁盘在交互模式中,可以输入help来查看帮助信息,或输入
help 指令来查看某条指令的帮助信息。可以使用tab键来补全命令,也可以连按两次tab命令来显示可用指令。
1、新建分区
mklabel gpt # 创建GPT分区表
输入print或p查看分区包信息

输入mkpart回车,然后按照提示依次输入分区名称、文件系统类型、去世位置,结束位置。

也可以一次性设置好
mkpart part2 ext2 2G 5G # 分区名称为part2 # 文件系统为ext2 # 起始位置和结束位置分别为2G、5G,所以分区容量为3G输入p查看一下分区情况

分区1的起始位置为1049kB,1MB==1024KB,。。。(不知道为啥,不纠结,过!)
分区的起始位置和结束位置也可以通过百分比的方式来指定。比如:
mkpart part3 ext2 5G 100% # 将5G之后的空间全部分给分区3
2、设置默认单位
输入
unit,回车,根据提示输入要更改的单位。unit % # 也可以写在一行
交互模式下更改单位就不是临时的啦,后面在使用print查看时也会按照现在更改的单位来显示。
3、更改分区名称
输入name回车,然后根据提示输入分区编号,新名称。
name 1 part111 # 也可以写在一行
4、配置分区标记
输入set,然后根据提示依次输入分区编号、标记类型、on或off(打开或关闭)。同样的在输入标记类型时也可以连按两次tab键来查看支持的类型。
set 1 diag on # 也可以写在一行中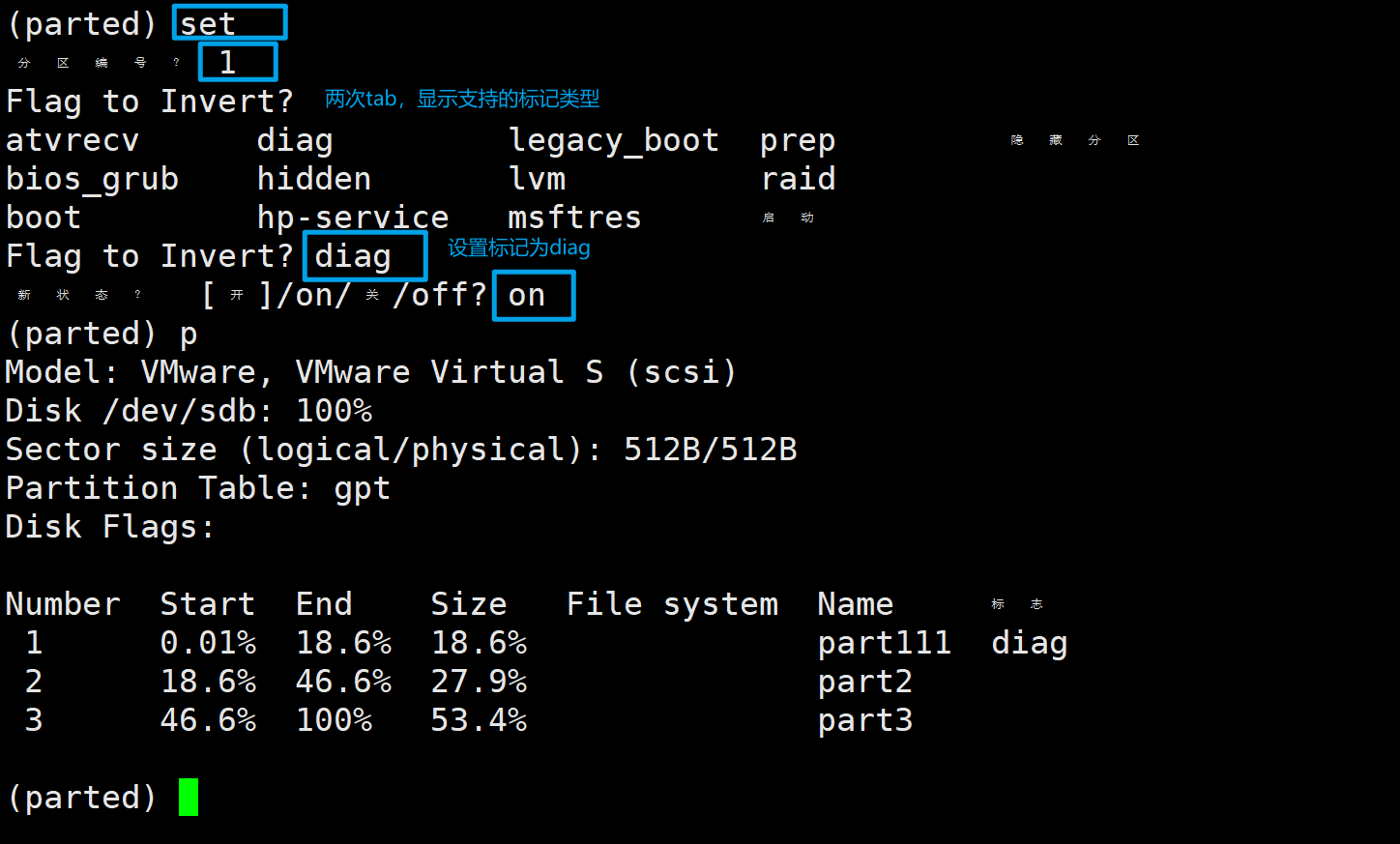
取消标记的操作域配置时类似,在新状态的提示中输入off表示取消标记。

5、删除分区
输入rm回车,然后根据提示输入要删除的分区编号。
rm 1 # 也可以写在一行,直接执行
GPT分区参考文章:parted分区命令_information: you may need to update /etc/fstab.-CSDN博客
5、LVM逻辑卷管理
LVM的作用:将物理上离散的空间整合为逻辑上连续的空间。
任何管理员在按照传统方式管理磁盘、为磁盘分区时,都难以精确地评估和分配磁盘各个分区的容量,随着时间的推移,需要存储的文件也会越来越多,磁盘空间总会有不足的一 天。此时可先将文件存储到其他分区中,再通过符号链接获取文件位置,或通过分区调整工具调整分区的大小。这两种方式的操作步骤看似简单,但可操作性极为有限。
为了解决上述问题,人们提出了逻辑卷管理机制(Logical Volume Manager,LVM)。 LVM 是 Linux 系统管理磁盘分区的一种机制,它建立在磁盘和分区之上,可以帮助管理员动态地管理磁盘,提高磁盘分区管理的灵活性。
LVM 机制弱化了磁盘分区的概念,它首先将多个物理卷(由磁盘分区转换而来)连接 为一个整块的卷组(volume group),形成一个存储池,此时管理员可主动设置卷组的存储单位(物理长度,Physical Extent,简称 PE),LVM 默认 PE 大小为4MB。 之后管理员可在卷组上随意创建逻辑卷组(logical volume),并进一步在逻辑卷组上创建文件系统。 LVM模型如图所示。

LVM 允许管理员调整存储卷组的大小,并按逻辑卷组进行命名、管理和分配。当系统中添加新的磁盘后,管理员不必将原有的文件移动到新的磁盘,只需直接扩展文件系统容量,即可使用新的磁盘。
下面对实现 LVM 机制常用的命令进行讲解。
(1)pvcreate
pvcreate命令用于将磁盘分区初始化为物理卷,该命令的语法格式如下:
pvcreate [选项] 参数pvcreate命令的参数通常为磁盘分区名,该命令的常用选项如下表所示。
选项 说 明 -f 强制创建物理卷,不需要用户确认 -u 指定设备的UUID(Universally Unique Identifier,通用唯一识别码) -y 所有的问题都用yes回答 -z 是否使用前4个扇区(y/n) pvcreate命令的用法示例如下:
# 将/dev/sdc2初始化为物理卷 pvareate /dev/sdc2(2)vgcreate
vgcreate命令用于将物理卷整合为卷组,该命令的语法格式如下:
vgcreate [选项] 卷组名称 物理卷路径1 物理卷路径2…vgcreate命令的常用选项如下表所示。
选项 说 明 -1 设置卷组上允许创建的最大逻辑卷数 -p 设置卷组上允许添加的最大物理卷数 -s 设置卷组上的最小存储单元(PE) vgcreate命令的用法示例如下:
#将物理卷/dev/sdc2、/dev/sdc4整合为卷组,并命名为itcast vgcreate itcast /devsdc2 /dev/sdc4 #将物理卷/dev/sdc2、/dev/sdc4整合为卷组,设置最小存储单元为8MB,并命名为itcast vgcreate -s 8M itcast /dev/sdc2 /dec/sdc4 #将物理卷/dev/sdc2、/dev/sdc3、/dev/sdc4整合为卷组,并命名为itcast vgcreate itcast /dev/sdc2 /dev/sdc3 /dec/sdc4 vgcteate itcast /dev/sdc{2,3,4} # 也可以这样(3)Ivcreate
lvcreate命令的功能是在已经存在的卷组中创建逻辑卷,该命令的语法格式如下:
lvcreate [选项] 卷组名/路径 物理卷路径lvcreate命令的常用选项如表所示。
选项 说 明 -l 以PE为单位指定逻辑卷容量 -L 指定逻辑卷的容量,单位为B/S/K/M/G/T/P/E -n 指定逻辑卷的名称 lvcreate命令的用法示例如下:
# 在卷组itcast上创建容量为2GB的逻辑卷my_lv1 lvcreate -L 2G -n my_lv1 itcast使用以上命令后,若逻辑卷创建成功,则可通过设备文件/dev/itcast/my_lv1进行访 问。基于LVM机制创建的逻辑卷同样需要先挂载到系统目录中才能被使用。
(4)vgdisplay
vgdisplay 命令用于显示LVM卷组的信息,该命令的格式如下:
vgdisplay [选项] 卷组vgdisplay 命令的常用选项如表所示。
选项 说 明 -S 使用短格式输出信息 -A 仅显示活动卷组的属性 vgdisplay命令的用法示例如下:
# 查看卷组itcast的属性 vgdisplay itcast
(5)Ivextend
当逻辑卷的可用存储空间不足时,需要为其拓展存储空间。使用LVM 机制管理磁盘时可通过lvextend命令动态地调整分区的大小,该命令的格式如下:
lvextend [选项] 逻辑卷lvextend命令的常用选项如表所示。
选项 说 明 -l 以PE为单位指定逻辑卷容量 -L 指定逻辑卷的容量,单位为B/S/K/M/G/T/P/E lvextend命令的用法示例如下:
# 为逻辑卷my_lv1增加1GB的空间 lvextend -l +1G /dev/itcast/my_lv1 # 将逻辑卷my_lv1扩展至5G lvextend -L 5G /dev/itcast/my_lv1(6)lvremove
lvremove命令用于删除指定的LVM 逻辑卷,若逻辑卷已经被挂载到系统中,则应先使用umount 命令将其卸载,再进行删除。 lvremove命令的语法格式如下:
lvremove [选项] 逻辑卷lvremove命令的常用选项为-f,其功能为强制删除指定逻辑卷。
Ivremove命令的用法示例如下:
# 删除逻辑卷my_lv1 lvremove /dev/itcast/my_lv1若不添加-f选项,使用以上命令后系统会给出询问信息,并在得到确认回复后才会删除指定逻辑卷。
若卷组不再使用,则可通过
vgremove命令删除指定卷组;若物理卷不再使用,则可使用pvremove命令删除指定物理卷。需要注意的是,创建 LVM 分区时会依次创建物理卷、 卷组和逻辑分区,删除时应逆向删除,即先删除逻辑分区、卷组,最后再删除物理卷。6、RAID磁盘阵列
根据磁盘中数据的存取方式,RAID 分为多个级别,其中较为常用的级别有 RAID0、 RAID1、RAID10、RAID5 等。
(1)RAID0
RAID0最少需要两块磁盘,这种方式的工作原理是在多个磁盘中分散存放连续的数据,多个磁盘并行执行数据存取,因此磁盘的性能会得到显著提升。 RAID0 存储机制如

RAID0 的存取效率较高,但不具备容错能力,若一块磁盘损坏,可能会影响整块数据的存储,因此适用于对成本和效率要求较高,但对可靠性要求较低的场景。
(2)RAID1
RAID1 同样至少需要两块硬盘,这种方式的工作原理是将数据同时复制到每块硬盘中,因此 RAID1 也被称为不含校验的镜像存储。使用 RAID1 方式存储时,只要有一块磁盘可用,便能保证正常工作。 RAID1 存储机制如图所示。

与 RAID0 相比,RAID1 可在一定程度上保证数据的安全性与完整性,但其磁盘利用率与写入的效率都比较低。
(3)RAID10
RAID10 不是 一种独立的分类,它由 RAIDO 和 RAID1 结合而成,兼具 RAID0 与 RAID1 高效与安全的特点。 RAID10 又称镜像与条带存储,这种方式至少需要4块硬盘,它又分为两种结构,即RAID1+0 与 RAID0+1。
-
RAID1+0 优先将数据按照 RAID1 方式备份,再将两部分数据组合为RAID0;
-
RAID0+1 先使用一半磁盘按RAID0 方式存储数据,再使用另外一半磁盘备份数据。
RAID10 继承了RAIDO 和 RAID1 的优点,是一种高可靠性、高效率的阵列技术,但成本高,也无法避免 RAID1磁盘利用率较低的缺点。

(4)RAID5
RAID5 可以视为 RAID10 的低成本方案,这种方式将数据以块为单位同步分别存储到 不同的磁盘中,并采用循环偶校验独立存储的方式,将各块数据的校验信息分别存储到 RAID5 的各个磁盘中,若其中一个磁盘的数据发生损坏,利用剩下的磁盘和相应的校验信 息可重新生成丢失的数据。 RAID5 至少需要3个磁盘,其结构如图2-8所示(其中b 表示数据块,p 表示校验信息)。

与普通磁盘相比,RAID5 可在一定程度上实现数据的并行存取,但在写数据时,RAID5 需要产生4项读/写操作,包括两次旧数据与校验信息的读取,两次新数据与校验信息的写入。综上所述,与其他磁盘阵列相比,无论是存储成本还是读写效率,RAID5 都位于中间水准。
(5)创建RAID
Linux系统中使用
mdadm命令创建和管理 RAID, 该命令的全称是 mltiple devices admin,其语法格式如下:mdadm [模式] <RAID 设备名> [选项] <组件设备名>mdadm 命令的模式即工作模式,该命令的工作模式如表所示。
工作模式 说 明 -A/--accemble 组合。组装一个预先存在的阵列 -B/--build 构建。构建一个不需要超级块的阵列,阵列中的每个设备都没有超级块 -C/--create 创建。创建一个新阵列 -F/--follow/-monitor 监视。监视一个或多个阵列的状态 -G/--grow 增长。更改RAID的容量或阵列中的设备数目 -auto-detect 自动侦测。请求内核启动任何自动检测的阵列 -I/--incremental 增加。向阵列中添加单个设备,或从阵列中删除单个设备 mdadm 命令在-C 模式下的常用选项如表2-33所示。
选项 说 明 -l 指定RAID级别 -n 指定设备数量 -a 是否自动为其创建设备文件 -c 指定数据块大小 -x 指定空闲盘个数,空闲盘可自动顶替损坏的工作盘 需要注意的是,在创建阵列时,阵列所需磁盘数为-n 指定的设备数量和-x 指定的空闲盘数量之和。
创建不同级别的 RAID 对磁盘或分区的数量要求不同,因此在创建 RAID 之前应先进 行规划,选择RAID 级别,并配置相应数量的磁盘,或将一个磁盘划分为多个分区,以实现软件RAID。
目前 Linux 系统支持的 RAID 级别有 RAID0、RAID1、RAID4、RAID5、RAID6、RAID10。 下面以RAID0 为例,对RAID 的创建方式进行讲解。
若要创建基于硬件的RAID0, 则系统中至少要有两块空闲磁盘;若要创建基于软件的 RAID0, 系统中至少要有两个空闲分区。以创建软件 RAID0 为例,我们先使用分区命令 fdisk在系统中创建两个空闲分区/dev/sda5 和/dev/sda6,之后使用这两个分区创建一个名 为/dev/md0 的 RAIDO 级别磁盘阵列,具体命令如下:
[root@localhost ~]# mdadm -C /dev/md0 -l 0 -n 2 /dev/sda5 /dev/sda6若以上命令执行成功,系统会提示"mdadm:array /dev/md0 started.",表示 md0 创建并启动成功。此时用户可使用"mdadm -detail /dev/md0"命令查看 mdo 的详细信息,终端的打印信息如下:


使用mdadm命令创建的磁盘阵列的用法与普通磁盘或磁盘分区相同,同样需要经过格式化与挂载。
7、补充
lsblk命令
lsblk命令可以查看磁盘的分区情况

lsblk -f显示更详细的信息

磁盘情况查询
查询系统整体磁盘使用情况
df -h
查询指定目录的磁盘占用情况
du -h 目录 # 默认为当前目录选项 作用 -s 指定目录占用大小汇总 -h 带计量单位(例如k、M、G) -a 含文件 --max-depth=1 子目录深度,等号后面指定深度 -c 列出明细的同时,增加汇总值 
实用指令
1、统计home文件夹下文件的个数
ls -l /home/ | grep "^-" | wc -l # ls -l 列出目录下的文件和目录的详细信息 # 将ls的结果交给grep进行过滤。 # "^-"是正则表达式,表示匹配行首为"-"的行。ls -l中"-"开头的就表示文件,d开头的表示目录。 # 将过滤后的数据交给wc类型处理,-l选项用于统计行数。
2、统计home目录下的目录个数
ls -l /home/ | grep "^d" | wc -l
3、统计home目录下文件的个数,包括子文件夹里的
ls -lR /home/ | grep "^-" | wc -l # ls的-R选项可以递归的显示子目录里的内容4、统计home目录下目录的个数,包括子目录里的
ls -lR /home/ | grep "^d" | wc -l5、以树状显示目录结构
tree /home # 如果没有tree命令,可以使用yum进行安装 yum install tree
十、任务调度
任务调度是指系统在某个之间执行的特定的命令或程序
任务调度的应用场景:
- 系统工作:有些重要的工作必须周而复始的执行,如病毒扫描等。
- 个别用户工作:个别用户可能希望定时执行某些程序,比如对mysql数据库的备份。
1、crond 任务调度
crond任务调度示意图

语法:crontab [选项]选项 作用 -e 编辑crontab定时任务 -l 查询crontab任务 -r 删除当前用户所有的crontab任务 service crond restart # 重启任务调度用法:
- 设置任务调度文件:/etc/crontab。(已经存在了,不需要管)
- 设置个人任务调度。执行crontab -e命令,编辑任务调度文件。
- 将需要执行的任务的指令写入到文件中。(编写文件时的操作与vi编辑器的操作时一样的)
指令的格式:
5个占位符****** 需要执行的命令5个占位符说明:每个占位符之间用空格隔开

简记为:分、时、天、月、星期
占位符中的一些特殊符号:

案例:

倒数第二条命令
*/10 4 * * *,就是4点整、4点10分,20分、30分、40分、50分都执行一次命令。应用实例:
1、每隔一分钟,将当前的日期信息,追加到/tmp/mydate文件中
crontab -e 然后编辑加入以下内容: */1 * * * * date >> /tmp/mydate 然后:wq保存退出即可2、每隔一分钟,将当前日期和日立都追加到/home/mycal文件中
# 方案一: vim my.sh # 创建一个脚本文件 在脚本文件中编写以下两行内容 date >> /home/mycal cal >> /home/mycal 然后:wq保存退出 chmod chmod 'u+x' my.sh # 给文件的拥有者添加执行权限 crontab -e 然后添加以下内容: */1 * * * * /home/my.sh # 每分钟执行一次my.sh文件 # 方案二: 直接在crontab -e中添加以下两行内容 */1 * * * * date >> /home/myca1 */1 * * * * cal >> /home/myca13、每天凌晨2:00将mysql数据库testdb,备份到文件中。
在crontab中添加以下内容: 0 2 * * mysqldump -u root -proot testdb > /homed/db.bak 由于没有安装数据库这段内容添加后会提示错误,也没必要添加,知道该怎么备份数据库就行。 第一个root是用户名,-proot的root是密码。2、at 定时任务
at命令是一次性定时计划任务,at的守护进程atd会以后台模式运行,检查作业队列来运行。
默认情况下,atd守护进程每60秒检查作业(任务)队列,有作业时,会检查作业运行时间,如果时间与当前
时间匹配,则运行此作业。at命令是一次性定时计划任务,执行完一个任务后不再执行此任务了。
在使用at命令的时候,一定要保证atd进程的启动,可以使用相关指令来查看。
ps -ef # 查看当前正在运行的进程 ps -ef | greap atd # 过滤出atd进程

at命令格式
at [选项] [时间] # 回车后会出现提示符 at>输入要执行的命令 # 在at>提示符下输入需要定时执行的命令后,按两次Ctrl+D退出 # 提示,在交互式环境下,可以按Ctrl+Backspace来删除字符如果输入完命令后又按了一次回车,转入下一行,那么就只需要按一次Ctrl+D就行。按多了就会直接退出ssh远程连接的登录(在xshell上)。 at>命令 # 按了回车 at> # 此时只需要按一次Ctrl+D就可以了注意:当你使用
at命令提交了一个任务后,它会被添加到任务队列中等待执行。默认情况下,任务的输出不会在终端上显示。任务执行完成后,输出会被发送到通过电子邮件发送给你。你可以在你的邮件中查看任务的执行结果。选项:

时间:
时间可以通过下面6中方式来指定
- 接受在当天的hh:mm(小时:分钟)式的时间指定。假如该时间已过去,那么就放在第二天执行。例如:04:00
- 使用midnight(深夜),noon(中午),teatime(饮茶时间,一般是下午4点)等比较模糊的词语来指定时间。
- 采用12小时计时制,即在时间后面加上AM(上午)或PM(下午)来说明是上午还是下午。例如:12pm
- 指定命令执行的具体日期,指定格试为month day(月 日)或mm/dd/yy(月/日/年)或dd.mm.yy(日.月.年),指定的日期必须跟在指定时间的后面。例如:04:00 2021-03-1
- 使用相对计时法。指定格式为:now+count time-units,now就是当前时间,time-units是时间单位,这里能够是minutes(分钟)、hours(小时)、days(天)、weeks(星期)。count是时间的数量,几天,几小时。例如:now+5 minutes
- 直接使用today(今天)、tomorrow(明天)来指定完成命令的时间。
案例:
案例1:2天后的下午5点执行/bin/ls /home
[root@localhost ~]# at 5pm + 2 days at> /bin/ls /home<EOT> # 这个<EOT>是按Ctrl+D后出现的,不不是输入的命令补充:
/bin/ls与ls的区别在于前者指定了ls命令的完整路径,可以确保命令在at任务中正确执行,后者则是通过环境变量PATH中定义的路径来寻找ls命令的位置,来执行ls。案例2:atq命令来查看系统中没有执行的工作任务
[root@localhost ~]# atq 10 Sat Dec 16 17:00:00 2023 a root # 这里的10表示这是第10条job,前面九条没有显示出来,是因为已经被执行过了案例3:明天17点钟,输出时间到指定文件内比如/root/date100.log
[root@localhost ~]# at 5pm tomorrow at> date > /root/date100.log<EOT>案例4:2分钟后,输出时间到指定文件内比如/root/date200.log
[root@localhost ~]# at now + 2 minutes at> date > /root/date200.log<EOT>案例5:删除已经设置的任务,命令为
atrm 任务编号
at不仅可以执行命令,还可以执行shell脚本。
[root@localhost ~]# at now at> /root/my.sh十一、进程管理
1、ps
ps 是 Process Status的缩写。在命令行输入 ps 后再按回车键就能查看当前系统中正 在运行的进程。 ps 的命令格式如下:
ps [选项][参数]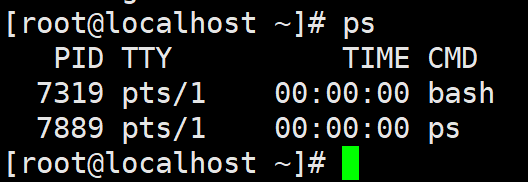
输出信息中包含4项:
- PID就是进程的 ID
- TTY 表明启动进程的终端机
- TIME 表示进程到目前为止真正占用CPU 的时间
- CMD 表示启动该进程的命令。
ps命令的旋律有两种风格:
- BSD风格:
选项 说 明 a 显示当前终端机下的所有进程,包括其他用户启动的进程 u 以用户的形式,显示系统中的进程 x 忽视终端机,显示所有进程 e 显示每个进程使用的环境变量 r 只列出当前终端机中正在执行的进程 - SysV风格:
选项 说 明 -a 显示所有终端机中除阶段作业领导进程(拥有子进程的进程)之外的进程 -e 显示所有进程 -f 除默认显示外,显示UID、PPID、C、STIME项 -o 指定显示哪些字段,字段名可以使用长格式,也可以使用"%字符"的短格式指定,多个字段名 使用逗号分隔 -l 使用详细的格式显示进程信息 2、top
top可以动态显示进程的相关信息,命令格式如下:
top [选项]top 命令可以实时观察系统的整体运行情况,默认时间间隔为3s,即 每 3s 更新 一 次界 面,类似 Windows 系统中的任务管理器。
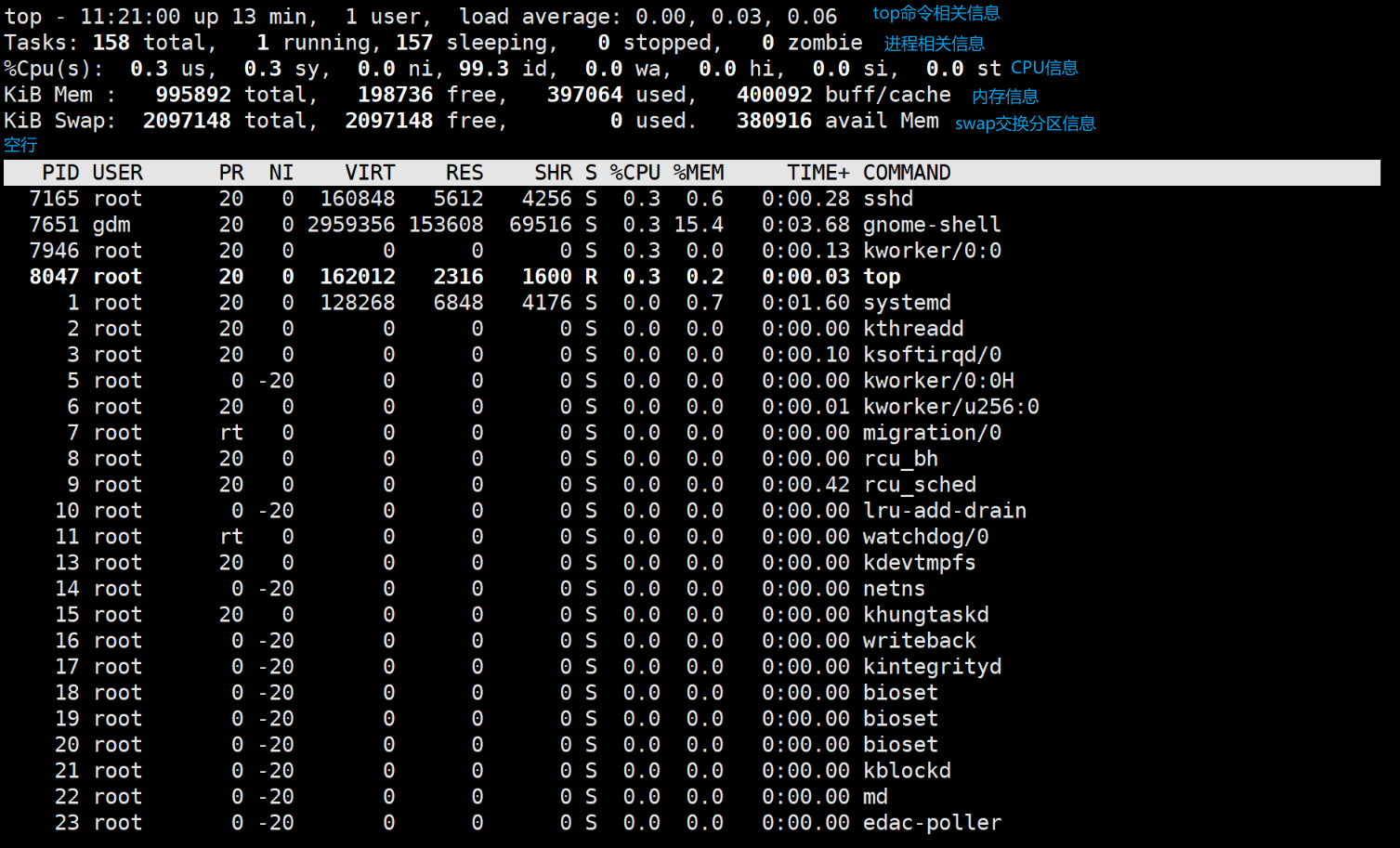
- 第一行中显示的是 top 命令的相关信息。
- 第二行显示与进程相关的信息。
- 第三行显示与CPU 相关的信息,若系统是单核的,则这条信息只有一行;若系统是双核或 多核的,则每个CPU 都会有对应的信息。
- 第四行显示与内存状态相关的信息。
- 第五行显 示 swap 交换分区的信息。
- 第六行是空行。
可以使用热键(l、t、m、)控制前五行信息的显示或隐藏,热键(M、P、T)可以根据以上某个选项对 top显示的信息进行排序。常用的热键对应的功能如下表:
热键 说 明 l 控制是否显示平均负载和启动时间(第一行) t 控制是否显示进程统计信息和CPU状态信息(第二、三行) m 控制是否显示内存信息(第四、五行) M 根据常驻内存集RES大小为进程排序 P 根据%CPU为进程排序 T 根据TIME+为进程排序 r 重置一个进程的优先级 i 忽略闲置和僵死的进程 k 终止一个进程 当使用热键r、k 时,第六行会给出相应的提示,并等待输入。
- top 的监测界面默认每隔3s刷新一次,读者可以使用选项-d 自定义刷新间隔;
- top 显 示的内容只有一屏,超出一屏的进程无法查看,若想查看更多进程的状态,可以使用选项-b, 该选项使用批处理的模式进行操作, 一次显示一屏,3s滚动一次;
- 若只想观察某段时间内的变化情况,可以使用选项-n 来指定循环显示的次数。
使用Ctrl+c可以结束top命令,回到命令行界面。
3、pstree
使用 pstree命令可以以树状图的形式显示系统中的进程,直接观察进程之间的派生关系。 pstree 命令的格式如下:
pstree [选项]选项 说 明 -a 显示每个进程的完整命令(包括路径、参数等) -c 不使用精简标识法 -h 列出树状图,特别标明当前正在执行的进程 -u 显示用户名称 -n 使用程序识别码排序(默认以程序名称排序) 4、pgrep
pgrep 命令根据进程名从进程队列中查找进程,查找成功后默认显示进程的 pid。 pgrep 命令的格式如下:
pgrep [选项] [参数]Linux 系统中可能存在多个同名的进程,pgrep 命令可以通过选项缩小搜索范围,其常用选项如表所示:
选项 说 明 -o 仅显示同名进程中PID最小的进程 -n 仅显示同名进程中PID最大的进程 -P 指定进程父进程的PID -t 指定开启进程的终端 -u 指定进程的有效用户ID 5、nice
进程的优先级会影响进程执行的顺序,在 Linux 系统中,可通过改变进程的 nice 值来更改进程的优先级。nice 命令的格式如下:
nice [选项] [参数]nice命令常用的选项为-n,n 表示优先级,是一个整数。 nice的参数通常为 一 个进程名。假设进程top的优先级为0,要修改bash 的优先级为5,则可以使用以下命令实现:
nice -n 5 bash # bash的优先级+5修改后可使用top命令检测 bash 的优先级。
nice命令不但能修改已存在进程的优先级,还能在创建进程的同时,通过设置进程的 nice值,为进程设定优先级。此时选项后的参数应为所要执行的命令。假设当前 top命令 的优先级已被设置为5,那么再次调用top 命令,修改其优先级为11,则应使用的命令如下所示:
nice -n 6 top # top的优先级+6当更改 nice值时,优先级PR和 nice值 NI 都会改变,其变化的规律为:新值=原值+ n,n 为本次命令中指定的 nice值。
6、jobs
Linux 系统中的命令分为前台命令和后台命令。所谓前台命令,即在命令执行后,命令 执行过程中的输出信息会逐条输出到屏幕,或命令打开的内容会替代原来的终端的命令,如压缩解压命令、top命令等;所谓后台命令,即命令执行后,不占用命令提示符,用户可继续 在终端中输入命令,执行其他操作的命令。
当前台命令正在运行时,以top 命令为例,按下快捷键Ctrl+Z, 终端会在输入如下所示 的信息后,才返回命令提示符:
[1]+已停止 top以上输出的是一个作业的状态信息,1表示作业号,“已停止”表示进程的状态。作业实际上也是进程, 一个作业中可能对应多个关联的进程。
在 Linux 系统中,使用jobs 命令可 以查看当前内存中的作业列表,jobs命令的语法格式如下:
jobs [选项] [参数]jobs命令的参数为作业号,该命令的常用选项如表所示。
选项 说 明 -l 显示进程号 -p 仅显示作业对应的进程号 -n 显示作业状态的变化 -r 仅显示运行状态的任务 -s 仅显示停止状态的任务 当选项和参数缺省时,默认显示作业编号、作业状态和作业名。
7、bg和fg
使用快捷键Ctrl+Z 也能将进程调入后台,但调入后台的进程会被暂时停止。若要将后台的命令调回前台继续执行,可以使用fg命令。 fg命令的格式如下:
fg 作业号fg命令的用法示例如下:
#将后台的进程top调回前台(假设 top进程的作业编号为1) [root@localhost~]# fg 1除快捷键外,也可以在命令后追加符号"&.",使进程在创建时直接被调入后台执行,其用法如下:
command & # command是命令的意思以 top命令为例,在执行命令时将命令调入后台的方式如下:
#在后台执行 top 命令 [rootelocalhost~]# top &8、kill
kill命令一般用于管理进程,它的工作原理是发送某个信号给指定进程,以改变进程的状态。 kill命令的格式如下:
kill [选项] [参数]kill命令的选项一般是“-信号编号”,参数一般是 PID。 除管理进程外,kill命令也可用于查看系统中的信号。使用kill命令的-l选项可以打印系统中预设的所有信号。下图为Centos7的信号列表。
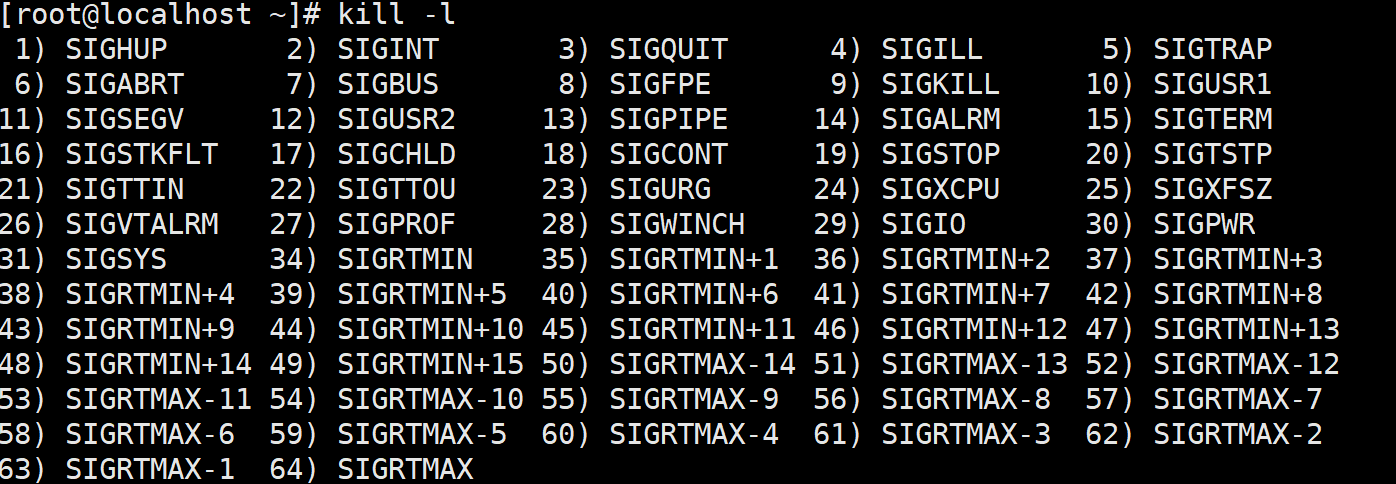
最常用的信号为9号信号 SIGKILL, 该信号不能被忽略,可以无条件终止指定进程。
除 SIGKILL 外,Linux 系统中常用的信号及其功能分别如下。
- SIGINT:中断进程,使用快捷键Ctrl+C 可实现相同功能。
- SIGQUIT:退出进程,使用快捷键 Ctrl+\ 可实现相同功能。
- SIGTERM:终止进程。
- SIGCONT:使已停止的进程继续执行。
- SIGSTOP:暂停进程,使用快捷键Ctrl+Z 可实现相同功能。
- kill命令默认发送15号信号(SIGTERM) 终止指定进程或作业。
kill命令的用法示例如下:
#终止PID为60053的进程 [root@localhost~]# kill -9 60053 # -9对应的信号为SIGKILL十二、服务管理
centos7及其之后使用systemctl命令管理服务,格式为:
systemctl 功能 服务名称 # 或者 systemctl 功能 服务名称.servicesystemctl命令功能的基础取值与含义如下:
- enable:使指定服务开机自启。
- disable:取消指定服务开机自启。
- start:启动指定服务。
- stop:停止指定服务。
- status:检查指定服务运行情况,列出该服务的详细信息。
- restart:重启指定服务。
- reload:重新加载指定服务的配置文件(并非所有服务都支持该参数,使用 restart 可实现相同功能)。

常见服务及其功能:
服务名称 说 明 dovecot 邮件服务器中POP3/IMAP服务的守护进程,主要用于收取邮件 httpd apache服务的守护进程 firewalld CentOS7及之后版本中防火墙服务的守护进程 mariadb mariadb数据库服务的守护进程 named DNS(域名系统)服务的守护进程,用于解析域名 network 网络服务的守护进程,用于管理网络 nfs NFS(网络文件系统)服务的守护进程,用于实现Linux系统间的文件共享 vsftpd vsftp服务的守护进程,用于实现文件传输(FTP服务) xinetd CentOS7及之后版本中的超级守护进程,用于管理多种轻量级Internet服务 postfix 邮件服务中IMAP服务的守护进程,主要用于实现邮件发送 

以network服务为例:
注:在linux中,执行完命令后,若没有提示,那么大部分情况下代表命令执行成功了。
1、关闭network服务
systemctl stop network # 如果你正在使用远程连接的话,就不要执行,不然就断开连接啦2、开启network服务
systemctl start network3、取消network服务开机自启
systemctl disable network执行成功后,返回如下信息:
network.service is not a native service, redirecting to /sbin/chkconfig. Executing /sbin/chkconfig network off实际上,设置服务开机自启就是在 Linux 系统的/etc/system/system/ multi-user.target.wants/目录下创建了一个符号链接文件,系统开机时会读取该目录下的符号链接文件,开启相应服务。相应地,取消服务开机自启则是删除/etc/systemc/system/ multi-user.target.wants/目录下与指定服务相关的符号链接文件。
4、使network服务开机自启
systemctl enable network执行成功后,返回如下信息:
network.service is not a native service, redirecting to /sbin/chkconfig. Executing /sbin/chkconfig network on5、查看network服务的运行状态
systemctl status network执行成功后,终端将打印如下信息:

以上信息中的 Active表示服务的状态,若值为 active(running)(文字为绿色),则表示 服务处于运行态;若值为 inactive(dead),则表示服务尚未开启。
需要说明的是,并非每次执行 systemctl都能成功启动服务,在管理服务时常常会看到如下所示的信息:
Job for named.service failed because the control process exited with error code, See "systemctl status named.service" and"journalctl -xe" for details. # 翻译: named.service的作业失败,因为控制进程退出并显示错误代码,有关详细信息,请参阅"systemctl status named.service"和"journalctl -xe"。终端输出以上信息后返回,说明此次命令执行失败。此时可使用 systemctl 的 status 功能,或通过journalctl-xe查看服务的报错信息,以便更快地定位到问题所在位置。
十三、软件包管理
RPM软件包管理
RPM 软件包分为两种:二进制包与源码包。二进制包中封装的是编译后生成的可执 行文件,类似于 Windows 操作系统下的.exe 文件,此种软件包可使用 rpm 命令直接安装; 源码包中封装的是源代码,在安装前需先安装源码包以生成源码,再对源码进行编译生成后 缀名为.rpm 的 RPM 包,之后才能安装软件本身。相比之下,二进制包的安装更加简单、方 便,安装速度也更快。
RPM 软件包使用通用的规则命名,通常包名遵循如下格式:
name-version-arch.rpm name-version-arch.src.rpm- name 表示软件包名;
- version表示软件版本号,通常遵循格式"主版本号. 次版本号.修正号";
- arch表示包的适用平台,RPM 包支持的平台有 i386、i586、i686、sparc、 aplha;(i386指的应该是x86架构的i3处理器)
- .rpm 与 .src.rpm 是 RPM 包的后缀,后缀.rpm 表示二进制包,后缀.src.rpm 表示源 码包。
具体示例如下:
acl-2.2.39- 1.1.1386.rpm jdk-8u144-linux-x64.src.rpm除以上内容外,用户也可能在包名中看到如下信息。
- el*:表示软件包的发行商版本,如 el5 表示软件包在 RHEL 5.x/CentOS 5.x下使用。
- devel:表示当前软件包是一个开发包。
- noarch:表示当前软件包适用于任何平台。
- manual:表示当前软件包是手册文档。
包含以上信息的包名示例如下:
mysql-community-release-e17-5.noarch.rpm epel-release-latest-7.noarch.rpm通过 RPM 可对软件包进行安装、删除、查询、更新和验证这5种操作,这些操作都通过 RPM 提供的命令——rpm 来实现。 rpm 命令与不同的选项搭配,可实现不同的功能,常用 的选项如表所示。
选项 说 明 -i 安装指定的一个或多个软件包 -q 查询软件包信息 -e 卸载指定的软件包 -v 显示安装过程 -V 验证已安装软件包内文件与原始软件包内文件是否一致 -a 查询已安装的包 -U 升级指定软件包 -c 显示软件包的所有配置文件列表 -d 显示软件包的所有文本文件列表 -p 查询软件包安装后对应的包名,通常和其他选项组合使用 g <组列表>查询组里有哪些软件包 -f <文件列表>查询文件属于哪个软件包 -l 显示软件包的文件列表 -s 显示软件包的文件状态 -h 以#号显示安装进度 选项可以组合使用,下面以安装JDK为例:
1、安装
到 Orcale官网(Java 下载 |Oracle 中国)下载jdk的rpm包,这里以jdk-21为例。

如果是在windows上下载的,可以通过xftp软件传输到虚拟机,或者通过共享文件夹传入。如果虚拟机centos系统安装了图形化界面,也可以直接在浏览器中下载。
切换到root用户,找到jdk文件的位置,进行安装:
rpm -ivh jdk-21_linux-x64_bin.rpm # jdk-21_linux-x64_bin.rpm是安装包的文件名,如果安装包没有在当前目录下,需要使用相对路径或绝对路径。包括后面的提示:如果后续命令中出现
错误:打开 jdk-21_linux-x64_bin.rpm 失败: 没有那个文件或目录的提示,那就请使用绝对路径试试。上述命令将-i、-v、-h这3个选项组合使用,命令执行后会显示安装过程的详细信息,并以“#”符号显示安装进度,安装信息如下所示:

2、查询
-q是执行查询操作时最常使用的选项,它通常与其他选项组合使用来完成不同的查询功能。例如,通过组合-qp 查询软件包安装后对应的包名,具体操作如下:
rpm -qp jdk-21_linux-x64_bin.rpm
由查询结果可知,jdk 软件包安装后对应的包名为jdk-21-21.0.1-12.x86_64。
rpm 还可以查询某个软件是否安装,在不知道具体包名的情况下,它可以与 grep命令 结合使用,通过关键字对查询结果进行筛选。例如,通过组合-qa 查询 JDK 是否安装,具体操作如下:
rpm -qa | grep jdk
由查询结果可知,系统中已经安装了JDK。
3、验证
rpm 命令的验证可以分为两种: 一种是安全性验证,主要验证下载的安装包是否安全 (是否包含有毒文件、文件是否已损坏等),这种验证通常用于安装之前;另一种是完整性验证,主要验证安装的软件包文件与原始软件包中的文件是否一致,这种验证用于安装之后。 下面将通过示例分别演示这两种验证的实现方式。
(1)安全性验证
以jdk-21_linux-x64_bin.rpm 是否安全为例:
rpm -K jdk-21_linux-x64_bin.rpm
shal md5 审验结果为“确定”,表明此安装包是安全的。
(2)完整性验证
rpm -Vp jdk-21_linux-x64_bin.rpm
以上命令执行后没有输出信息,直接返回终端,说明安装前后软件包中的文件信息一 致。假如对某个文件做了修改或进行了改动,再次验证时就会输出验证结果。
例如,在JDK 安装后,进入软件安装目录/usr/java,删除 README 文件并再次验证,具体操作如下:

这里要使用绝对路径,因为我当前并没有在/opt目录下。
4、更新
若要更新软件包,需先下载一个高版本的软件包,再搭配-U 选项(-U 通常与-vh 组合使 用)执行 rpm 命令安装高版本的软件包。在安装时,RPM 会先将旧版本的软件包从系统中 移除,再安装新版本的软件包,以实现版本更新。更新过程与安装过程一致,读者可以自行 下载更高版本的JDK 软件包尝试更新,此处不再演示。
5、删除
删除软件包时需使用-e 选项。 rpm 支持一次删除多个软件包,删除软件包时指定的包名同样是原始软件包安装后对应的包名。例如,删除刚才安装的JDK 软件时,选项-e 指定的包名应为
jdk-21-21.0.1-12.x86_64,具体操作如下:rpm -e jdk-21-21.0.1-12.x86_64
正常情况下,删除成功之后是没有输出的,本次删除出现警告是因为在之前的操作中删 除了README 文件。
删除完成之后再次以关键字jdk 查询时,终端将不会再打印包名
jdk-21-21.0.1-12.x86_64,具体如下所示:rpm -qa | grep jdk
需要说明的是,一些软件包不是独立使用的,它可 能与其他软件包存在依赖关系,在操作某个软件包时,需要同时处理与其有依赖关系的软件 包。然而,RPM 虽然能够通过-R 选项查看与指定包有依赖关系的包,但提示不够具体,因 此一般不使用RPM 管理存在依赖关系的软件包。
YUM软件包管理
与 RPM 相比,YUM 最大的优势就是可以自动处理软件包之间的依赖关 系。从CentOS5 开始,系统就默认安装 YUM, 所以在 CentOS7 中可以直接使用 yum 命令。yum玛里苟斯如下所示:
yum [options] COMMAND- options表示选项;yum 命令常用的选项是-y,使用该选项,安装过程中遇到的所有问题将自动给出肯定回答,避免用户手动一一确认;
- COMMAND 表示命令,常用的是安装、更新等。
面以安装 telnet工具(常用于测试端口)为例来演示yum 命令的用法。
1、安装
yum 的安装命令为 install,使用 yum 安装 telnet 的命令如下所示:
yum -y install telnetyum 命令在安装过程中它会自动解决依赖关系,下载目标软件包依赖的包,并进行安 装。若软件包成功安装,终端将会打印如下所示的提示信息。

2、查询
yum 常用的查询命令有两个: list和 info。
- yum list 用于列出一个或一组软件包;
- yum info用于显示关于软件包或组的详细信息。
下面分别展示这两个命令的用法。
(1)使用list查询telnet包
yum list telnet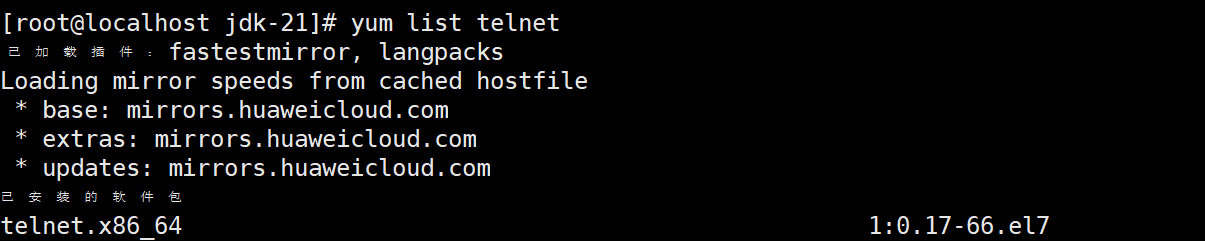
(2)使用info命令查询telnet包
yum info telnet
如果
yum list或yum info命令后面没有具体的包名,终端将会打印系统中所有包的信息。除基础查询外,yum 还可以使用 check-update 命令查询是否有可用的软件包更新,具体如下所示:
yum check-update
3、更新
yum 的更新命令为update,用于更新系统中一个或多个软件包。以更新 telnet为例,具体操作如下:
yum update telnet
执行更新 telnet 的命令后,终端最后输出 No packages marked for update,说明本次没 有可用的更新包。这是因为yum 默认会选择安装源中最新的软件包进行安装,如果本次更 新与之前的安装操作使用相同的安装源,软件包不会被更新。若想使用yum 安装更高版本 的安装包,需要更换新的yum 源,关于yum 源的更换方法将在后面会详细讲解。
4、删除
yum 删除命令为 remove,用于从系统中删除一个或多个软件包。以删除 telnet为例,具体操作如下:
yum -y remove telnet
yum 在执行删除命令时也会自动处理依赖关系。
yum 还提供了 clean 命令用于清除缓存数据,它可以清除 RPM 包、RPM 头文件等 (clean [headers |packages |metadata |dbcache |plugins |expire-cache |all])。如果使用 all,则 清除使用yum 所生成的所有缓存文件,具体操作如下:
yum clean all
YUM源管理
YUM 之所以可以自动从服务器下载相应的软件包进行安装,是因为配置了相应的软件源。软件源也称为软件仓库,其本质为预先保存了软件包下载地址的文件,这些文件存储 在
/etc/yum.repos.d/目录下,使用ls命令可查看该目录下的软件源文件,具体操作如下:ls /etc/yum.repos.d/
以上命令的输出结果打印了CentOS7 默认配置的7个YUM 源文件,这些文件都以 .repo 为扩展名,因此yum 源也称为 repo文件。在.repo文件中,每个以
[]开始的部分都是 一个“源”。以CentOS-Base.repo文件为例,该文件中的一个“源”如下所示:可以使用cat或vim打开文件查看
上述“源”中各项含义的介绍分别如下
- [base]:命名一个叫 base的源。
- name:标识源的名字为CentOS-$releasever-Base。
- mirrorlist:记录源的镜像地址。
- baseurl:记录源的地址,此项支持 http、ftp、file 3种类型。
- gpgcheck=1:开启 gpg 验证
- gpgkey:定义 gpgkey 地址。
使用yum 安装软件时,yum 会从这些源中查找 RPM 软件包下载地址,如果源中没有 与目标软件相关的配置,则无法安装。
yum 源分为本地源和网络源,用户可手动配置 yum 源。若想配置本地源,则需下载 RPM 包到本地,再将 RPM 包的存储目录配置到 baseurl中;若想配置网络源,只需将 RPM 包的下载地址配置到 baseurl 中即可。
下面演示将yum源配置为阿里云镜像源
配置yum源为阿里云
1、切换到
/etc/yum.repos.d/目录下cd /etc/yum.repos.d/2、下载weget
yum install wget -y3、备份文件
mv CentOS-Base.repo CentOS-Base.repo.bak # 其实也就是重命名了(重命名后yum应该就不能用了)4、使用wget下载新的CentOS-Base.repo文件
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo5、清除缓存并生成新的缓存
# 清除缓存 yum clean all # 生成新的缓存 命令:yum makecache现在就将yum源配置为阿里云镜像源了。可以查看新的CentOS-Base.repo文件,发现里面的源的地址等、都变成阿里云的地址了。
vim CentOS-Base.repo
使用yum离线安装软件包(待补充)
离线安装pstree,含有pstree命令的工具包的名字不是pstree,使用search命令查找含有pstree命令的软件包名称。
使用DVD安装
# yum软件包镜像源 ls /etc/yum.repos.d/ 查看 cat /etc/yum.repos.d/CentOS-Media.repo # CentOS-Base.repo这个是镜像仓库地址的文件 将DVD挂载到这几个任意一个目录 baseurl=file:///media/CentOS/ file:///media/cdrom/ file:///media/cdrecorder/ 创建/media/cdrom/这个目录 mkdir /media/cdrom 将dvd挂载到这个目录 mount /dev/cdrom /media/cdrom/ 安装命令 yum --disablerepo=\* --enablerepo=c7-media [command] yum --disablerepo=\* --enablerepo=c7-media search ifconfig 使用seatch命令查找这个目录的软件包名然后再安装远程传输文件(待补充)
在Windows中打开cmd终端,使用cd命令切换到需要传输的文件的目录。或者直接打开文件所在的目录,右键,选择在终端中打开。
同时,使用Xshell连接到虚拟机或服务器。当然,也可以使用Windows的cmd终端连接(其他版本不知道可不可以,但是Win11是可以的),连接命令为
ssh 用户名@IP地址,例如ssh [email protected]。在cmd终端中使用命令
ftp 用户名@IP地址连接到虚拟机。出现ftp>提示符,说明连接成功啦。。。。。。使用ls命令可以查看运程主机的本地目录
查看远程ftp服务器上用户peo相应目录下的文件所使用的命令为:ls,登录到ftp后在ftp命令提示符下查看本地机器用户anok相应目录下文件的命令是:!ls。查询ftp命令可在提示符下输入:?,然后回车。
1、从远程ftp服务器下载文件的命令格式:
get 远程ftp服务器上当前目录下要下载的文件名 [下载到本地机器上当前目录时的文件名],如:
get nmap_file [nmap]意思是把远程ftp服务器下的文件nmap_file下载到本地机器的当前目录下,名称更改为nmap。
带括号表示可写可不写,不写的话是以该文件名下载。
如果要往ftp服务器上上传文件的话需要去修改一下vsftpd的配置文件,名称是vsftpd.conf,在/etc目录下。要把其中的“#write_enable=YES”前面的“#”去掉并保存,然后重启vsftpd服务:
sudo service vsftpd restart。2、向远程ftp服务器上传文件的命令格式:
put 本地机器上当前目录下要上传的文件名 [上传到远程ftp服务器上当前目录时的文件名],如:
put sample.c [ftp_sample.c]意思是把本地机器当前目录下的文件smaple.c上传到远程ftp服务器的当前目录下,名称更改为ftp_sample.c。
带括号表示可写可不写,不写的话是以该文件名上传。
第五章 Shell
一、Sehll概述
Shell 可接收用户输入的命令,将 命令送入内核中执行。内核接收到用户的命令后 调度硬件资源完成操作,再将结果返回给用户。
传递命令时,Shell将命令解 释为二进制形式;返回结果时,Shell将结果解释 为字符形式,因此 Shell 又被称为命令解释器。

Linux 中 Shell 种类很多,常见的 Shell 有 Bourne Shell(sh)、Bourne-Again Shell (bash)、C Shell(csh/tcsh)、Korn Shell(ksh)、Z Shell(zsh)几种。
bash是linux默认的shell,下面所要学习的都是bash。
使用cat命令查看/etc/shells文件中的内容,可确定主机支持的shell类型。
cat /etc/shells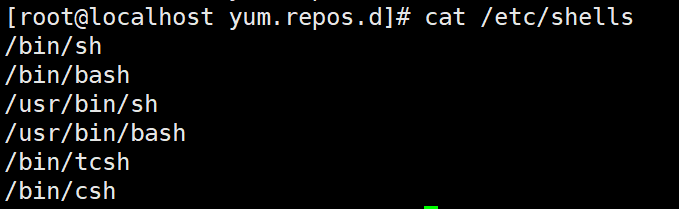
使用echo命令打印本机当前正在使用的Shell,但无法显示子shell。
echo $SHELL
直接输入shell的文件名就可以开启一个新的shell,新的shell是当前shell的子shell或下级shell。可以通过psml来查看当前系统中运行的所有shell,包括子shell。
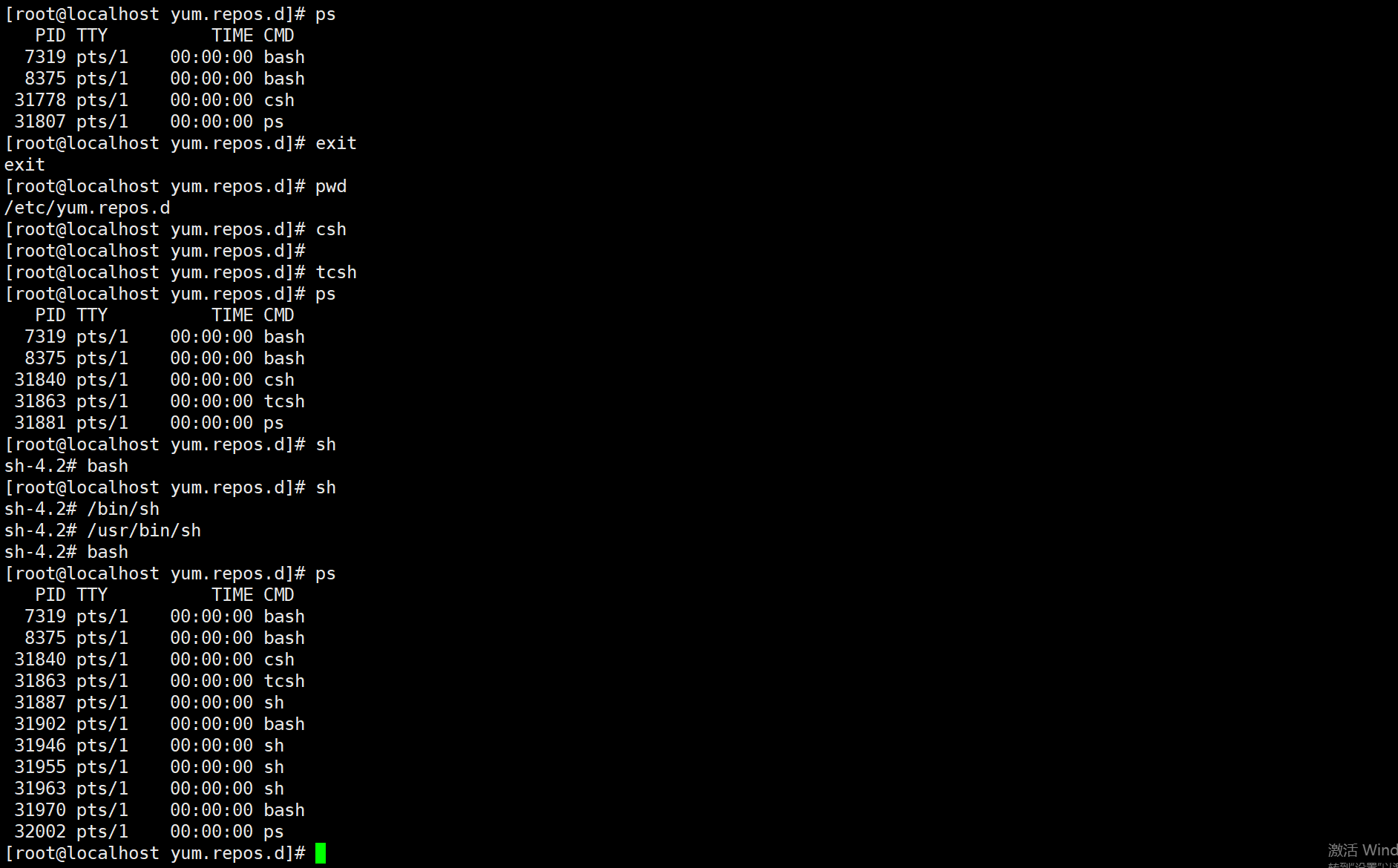
使用exit命令可以退出当前shell。

Shell的使用技巧
1、自动补齐
利用Tab 键可以根据输入的字符串自动查找匹配 的命令、文件、目录等,如果匹配结果唯一,Shell会自动补齐;如果有多个可以匹配的名称, 按两次Tab 键后 Shell会列出所有匹配项。
2、查找命令行历史记录
Shell提供了4种方法查找命令行历史记录,具体如下所示。
(1) 查找家目录下的.history文件,Shell在执行命令时将命令的操作记录保存在用户 家目录下的.bash history文件中,通过这个文件可以查询 Shell命令的执行历史。
(2) 使用 history命令,Shell提供了history命令用于查询命令行历史记录。
(3) 使用键盘上下方向键,通过键盘上的上下方向键可以逐条查询命令行历史记录。 如果要重新执行不久前执行的命令,使用上下方向键查找更方便。
(4) 使用快捷键 Ctrl+R, 按下此快捷键,会出现 reverse-i-search 提示,输入之前执行 过的命令,每当输入一个字符,终端都会滚动显示历史命令,当显示到想要查找的命令时直 接按回车键就执行了该命令。不想查找时,按 Esc 键或方向键退出查找。
3、命令替换
在进行 Shell编程时经常会用到命令替换,命令替换有两种方式:反引号``和$() 符号。
反引号在Esc 键下方,它的作用是将命令字符替换为命令的执行结果。例如,替换 Is 命令,输出当前目录下的文件和目录。
echo `ls` echo $(ls)
4、I/O重定向
Linux 系统中的输入输出分为以下3类:
- 标准输入(STDIN), 标准输入文件的描述符是0,默认的设备是键盘,命令在执行时从标准输入文件中读取需要的数据。
- 标准输出(STDOUT), 标准输出文件的描述符是1,默认的设备是显示器,命令执行后其输出结果会被发送到标准输出文件。
- 标准错误(STDERR), 标准错误文件的描述符是2,默认的设备是显示器,命令执行时产生的错误信息会被发送到标准错误文件。
Linux允许对以上3种资源重定向。所谓重定向,即使用用户指定的文件,而非默认资 源(键盘、显示器)来获取或接收信息。
(1)输入重定向<、<<
输入重定向运算符“<”可以指定其右值为左值的输入,具体格式如下:
命令 0< 文件名其中0是标准输入文件标识符,可以被省略。以wc 命令为例,将file中的内容作为命令 wc 的输入,统计文件中的行数。
wc -l < file(2)输出重定向>、>>
输出重定向运算符“>”可以将其右值作为左值的输出端,其格式如下:
命令 1> 文件名其中1是标准输出文件标识符,也可以被省略。以 cat命令为例,将/etc/passwd文件中的 内容重定向到 file文件的具体操作如下:
cat /etc/passwd > file以上命令会将“cat /etc/passwd”的执行结果以覆盖的形式输出到 file 文件中。若想保留 file文件的内容,可以使用">>"运算符,以追加的形式将结果输出到 file文件。
cat /etc/passwd >> file若输出重定向的文件不存在,则会自动创建。
(3)错误重定向
错误重定向也使用">"符号,其格式如下:
命令 2> 文件名其中2是标准错误文件描述符,不可以被省略。例如,打开一个不存在的文件会报出错误信息,如果使用错误重定向可以将错误信息输出到文件中。下面打开不存在的文件 cfile,将其 错误信息重定向到文件newfile中,命令如下所示:
cat cfile 2> newfile执行该命令,屏幕上不会输出错误信息,错误信息被重定向到 newfile文件中了。查看newfile文件,结果如下:
cat newfile
同样,错误重定向也可以使用运算符">>",以追加的方式将错误输出到指定的文件。
5、管道
管道符号为“ | ”,它可以将多个简单的命令连接起来,使一个命令的输出,作为另外一个 命令的输入,由此来完成更加复杂的功能。其格式如下:
命令1 | 命令2 | … |命令n以 ls命令和 grep 命令的组合为例来演示管道符的使用,具体如下所示:
ls -l /etc | grep init在以上示例中,管道符“ | ”连接了ls命令和grep命令,其作用为:输出etc 目录下文件信息包含init关键字的行。若不使用管道,则必须使用两步来完成这个任务,具体步骤 如下:
ls -l /etc > tmp.txt grep init < tmp.txt二、Shell中的变量
Shell中常用的 变量有4种:本地变量、环境变量、位置变量和特殊变量。
1、本地变量
本地变量相当于C 语言中的局部变量,它只在本 Shell中有效,如果 Shell退出,本地变量将被销毁。
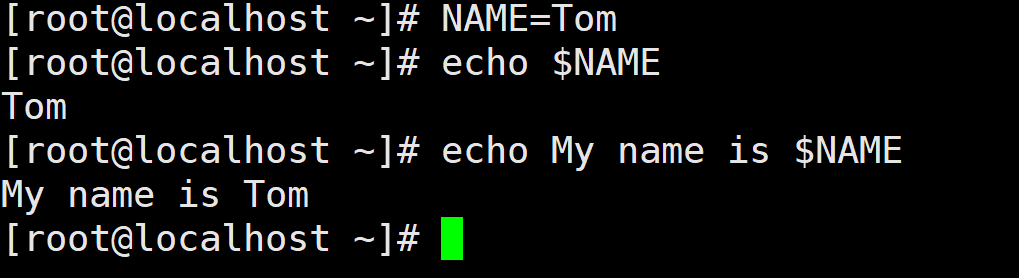
本地变量的定义格式如下所示:
NAME=valueNAME 是变量名,value是赋给变量的值。如果 value 没有指定,变量将被赋值为空字符串。在使用变量时,要在变量前面加“$”符号。例如,定义一个变量 NAME, 其值为 Tom, 在输出时,要以$NAME 的形式输出。
Shell支持连续输出多个变量的值,例如,再定义一个变量 AGE, 其值为19,然后同时输出变量NAME与AGE。

在定义本地变量时,还可以使用read命令从标准输入中读取变量值,其中 read 的-p 选项可以设置输入提示信息。

删除所定义的变量,可以使用unset命令。

调用 unset 命令删除 AGE 变量后,再输出该变量时值不再显示,仅输出一个空白行,表明这个变量已被删除(输出一个不存在的变量时也是输出一个空白行)。
总结:
# 定义,使用赋值号 NAME=value # 变量名好像不一定需要是大写 # 使用,在变量名前加$ echo $NAME # 删除unset unset NAME2、环境变量
环境变量是 Shell中非常重要的一个变量,用于初始化 Shell的启动环境。
(1)环境变量的定义与清除
环境变量在 Shell编程和 Linux 系统管理方面都起着非常重要的作用,它一般用来存储路径列表,这些路径可用于搜索可执行文件、库文件等。环境变量定义格式如下所示:
export ENVIRON-VAEIABLE=value环境变量必须要使用export关键字导出,export关键字的作用是声明此变量为环境变量。例如,定义 APPSPATH 变量并赋值为/usr/local,然后利用 export 将 APPSPATH 声明为环境变量。

在命令行中使用 export定义的环境变量只在当前 Shell与子 Shell中有效,Shell 重启后这些环境变量将丢失,如果需要永久更改,需要修改环境变量的配置文件(后面会讲)。
使用env 命令可以查看所有的环境变量,包括用户自定义的环境变量。

删除环境变量和删除本地变量的方式相同,也是调用unset命令。
总结:
环境变量的定义、使用和删除与本地变量类似,只是环境变量在定义时需要使用export关键字进行声明。
使用env可以查看所有的环境变量。
(2)几个重要的环境变量
bash 中预设了很多环境变量,其中有几个比较重要的环境变量,Linux 系统及诸多应用 程序的正常运行都依赖它们。
PATH
PATH 是 Linux 中一个极为重要的环境变量,它用于帮助Shell找到用户所输入的命令。用户输入的每个命令都是一个可执行程序,计算机执行这个程序以实现这个命令的功能。可执行程序存在于不同目录下,PATH 变量就记录了这一系列的目录列表。
输出 PATH 变量的值,结果如下所示:

由输出结果可知,PATH 中包含了多个目录,它们之间用冒号分隔,这些目录中保存着命令的可执行程序,例如,输入 ls命令,PATH 就会去这些目录中查找 ls命令的可执行程 序,首先在/usr/local/bin目录查找,找到就执行该命令;没找到就继续查找下一个目录,直 到找到为止。如果PATH 值存储的目录列表中的所有目录都不包含相应文件,则 Shell会 提示"未找到命令……"。
PATH 变量的值可以被修改,但在修改时要注意不可以直接赋新值,否则 PATH 现有 的值将会被覆盖。如果要在 PATH 中添加新目录,可以使用下面的命令格式:
PATH=$PATH:/newdrectory # 例如将目录/opt目录加到环境变量中 PATH=$PATH:/opt以上格式中$PATH 表示原来的 PATH 变量,new directory 表示要添加的新路径,中 间用冒号隔开,旧的 PATH 变量加上新增路径之后再赋值给PATH 变量。
PWD 和 OLDPWD
PWD 记录当前的目录路径,当利用cd命令切换到其他目录时,系统自动更新PWD的值,OLDPWD 保存旧的工作目录。输出这两个变量的值,结果如下所示:

从/root目录切换到根目录后,当前目录为/,之前所在的目录是/root。
HOME
HOME 记录当前用户的家目录,例如,在本机中有两个用户 root、abc,分别用这两 个用户输出$HOME 变量的值,具体如下所示:

SHELL
SHELL 变量的值是/bin/bash,表示当前的 Shell是 bash。 如果有必要使用其他Shell, 则需要重置 SHELL 变量的值。
USER 和 UID
USER 和 UID 是用于保存用户信息的环境变量,USER 保存已登录用户的名字,UID 则保存已登录用户的ID。 使用echo 命令打印这两个环境变量,具体如下所示:

PS1 和PS2
PS1 和 PS2 称为提示符变量,用于设置提示符格式。例如,“[itheima@localhost ~]$” 就是 Shell提示符,[]里包含了当前用户名、主机名和当前目录等信息,这些信息并不是固 定不变的,可以通过PS1 和 PS2 的设置而改变。
PS1 用于设置一级 Shell提示符,也称为主提示符。使用 echo命令查看 PS1 的值。

由以上输出结果可知,变量PS1 包含4项内容,这4项内容的含义分别如下:
- \u 表示即当前用户名;
- \h 表示主机名;
- \W 表示当前目录名;
\$是命令提示符,普通用户是$符号,如果是 root用户,命令提示符是#符号。
PS2 用于设置二级 Shell提示符,使用echo 命令查看PS2 的值,其结果如下所示:

PS2 的值为>符号,当输入命令不完整时,将出现二级提示符。

(3)环境变量的配置文件
Linux 中环境变量包括系统级和用户级,系统级的环境变量对每个用户都有效,而用户级的环境变量只对当前用户有效。环境变量的配置文件也分为系统级和用户级,系统级的文件有很多,例如/etc/profile、/etc/profile.d、/etc/bashrc、/etc/environment 等,在这些文件中定义的环境变量对所有用户都是永久有效的。用户级的环境变量配置文件主要是 .bash profile和 .bashrc两个文件,它们位于用户的家目录下。例如,以abc用户登录, 它们位于/home/abc/目录下,使用cat命令查看两个文件中的内容,具体如下所示:
注意:如果是从其他用户使用su命令切换到abc用户的,那么无法查看这个文件。需要直接使用abc用户登录,才能查看abc家目录下的这个文件。


.bash profile文件主要定义当前 Shell 环境变量, .bashrc 文件主要用于定义子 Shell 环境变量。如果当前 Shell创建了一个子 Shell,则 .bashrc 文件使得子 Shell的环境变量与 当前 Shell 的环境变相分离。
用户在上述文件中均可以定义永久有效的环境变量,但要区分开环境变量是对所有用户有效还是对当前用户有效。
3、位置变量
位置变量主要用于接收传入 Shell脚本的参数,因此位置变量也被称为位置参数。位置变量的名称由“$”与整数组成,命名规则如下所示:
$n$n 用于接收传递给 Shell脚本的第 n 个参数,如变量$1接收传入脚本的第一个参 数。当位置变量名中的整数大于9时,需使用{}将其括起来,如脚本中的第11个位置参数 应表示为${11}。位置变量是Shell 中唯一全部使用数字命名的变量。需要注意的是,n 是 从1开始的,$0表示脚本自身的名称。
接下来通过一个 Shell脚本来演示位置变量的用法,使用vi编辑器创建并编写test.sh脚本,内容如下:
#!/bin/bash echo "The script's name is : $0" # 脚本名 echo "Parameter #1: $1" # 第1个位置参数 echo "Parameter #2: $2" echo "Parameter #3: $3" echo "Parameter #4: $4" echo "Parameter #5: $5" echo "Parameter #6: $6" echo "Parameter #7: $7" echo "Parameter #8: $8" echo "Parameter #9: $9" echo "Parameter #10: ${10}" echo "Parameter #11: ${11}"注:“#”后的字符表示注释,除第一行外的注释都可以不写。
执行test.sh脚本并传入参数,输出结果如下:
bash test.sh a b c d e f g h i j k # 脚本按照位置接受参数,与编程语言中的函数类似。
在接受参数时,位置变量只根据位置来接受相应参数,比如修改 test.sh 脚本如下。
#!/bin/bash echo "The script's name is : $0" echo "Parameter #8: $8" echo "Parameter #9: $9" echo "Parameter #10: ${10}"再次执行脚本,参数与上一次相同,结果如下:

在传入的参数中,第8个位置是h,$8 读取到了相应位置的参数。如果传入的参数不足8个,那么$8值为空。参数传多了也不会报错。
4、特殊变量
除了上述几个变量之外,Shell还定义了一些特殊变量,主要用来查看脚本的运行信息。 Shell中的常用的特殊变量如下所示。
$#:传递到脚本的参数数量。$*和$@:传递到脚本的所有参数。$?:命令退出状态,0表示正常退出,非0表示异常退出。$$:表示进程的PID。
接下来修改 test.sh脚本来演示特殊变量的用法,在脚本中添加一些内容。
#!/bin/bash echo "The script's name is : $0" echo "Parameter #8: $8" echo "Parameter #9: $9" echo "Parameter #10: ${10}" # 新增代码 echo "Parameter count: $#" # 传递给脚本的参数的数量 echo "All parameter: $*" # 传递给脚本的所有参数 echo "All parameter: $@" # 传递给脚本的所有参数 echo "PID: $$" # 本程序的进程ID运行结果如下:
bash test.sh a b c d e f g h i j k
三、Shell中的符号
1、引号
在 Shell中,引号主要用来转换元字符的含义。所谓元字符,是指那些在正则表达式(正则表达式在后面会讲)中具有特殊处理能力的字符,如$、\、>等字符。
Shell 中的引号有3种:单引号(')、双引号("")与反引号()。接下来分别介绍这几种引号。
(1)单引号
单引号可以将它中间的字符还原为字面意义,实现屏蔽 Shell元字符的功能。引号里的字符串就是一个单纯的字符串,没有任何含义。例如,定义变量 NUM=100, 在输出变量时需要添加$符号,如果这个变量加上单引号输出,则直接将$符号与变量整体作为一个字 符串输出,命令如下所示:
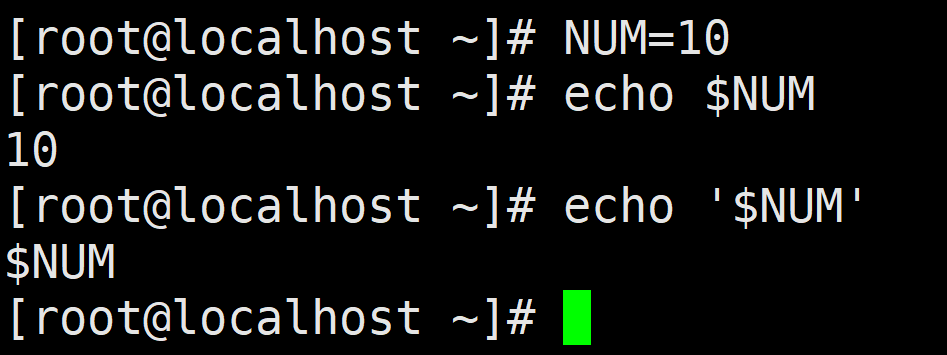
注意:不可以在两个单引号中间单独插入一个单引号,单引号必须要成对出现。
(2)双引号
双引号也具有屏蔽作用,但它不会屏蔽$符号、\符号``符号(反引号)。将刚才定义的变量NUM 加双引号输出,具体如下所示:

注意:双引号也可以屏蔽单引号的作用,在一对双引号中,单引号不必成对出现。
(3)反引号
反引号可以进行命令替换。反引号与双引号可以结合使用。例如,输出系统的时间,具体操作如下:

以上所示的命令中用到了命令 date,该命令的功能是打印系统当前的时间。
可以把反引号嵌入到双引号中,但是当把反引号嵌入到单引号中时,单引号会屏蔽掉反引号的功能。例如,把
date嵌入单引号中,将不会打印出当前的时间。
2、通配符
Shell的通配符一般用于数据处理或文件名匹配,常用的通配符如表所示。
符号 说 明 符号 说 明 * 与零个或多个字符匹配 [] 与 中的任一字符匹配 ? 与任何单个字符匹配 [!] 与[]之外的任一字符匹配 (1)通配符“*”
如果用户想要列出/etc目录下以sys开头的所有文件,可以使用如下命令:
ls -d /etc/sys*
在以上命令中,sys* 表示匹配以字符串 sys开头的所有文件。 -d选项表示仅对目标目录本身进行处理,不递归处理目录中的文件。
如果想输出以.conf结尾的所有文件,则可以使用如下命令:
ls /etc/*.conf
(2)通配符“?”
通配符"?"每次只能匹配一个字符,通常与其他通配符结合使用。如果想查找/etc目录 下文件名是由两个字符组成的文件,可以使用如下命令:
ls -d /etc/??
(3)通配符“[]”
通配符“[]”表示与[]中的任一字符匹配,它通常是一个范围。例如,在/etc 目录,列出 以 f~h范围的字母开头,并以.conf结尾的文件,可以使用如下命令:
ls /etc/[f-h]*.conf
(4)通配符“!”
通配符“[!]”表示除了[]里的字符,与其他任一字符匹配。例如,如果查找以 y 开头且不以.conf 结尾的文件,可以使用如下命令:
ls -d /etc/y*[!.conf]
3、连接符
Shell中提供了一组用于连接命令的符号,包括
;``&&以及||,使用这些符号,可以对多条 Shell指令进行连接,使这些指令顺序或根据命令执行结果有选择地执行。下面将对这些符号的功能分别进行介绍。(1)连接符“;”
使用“;”连接符间隔的命令,会按照先后次序依次执行。假如现在有一系列确定的操作需要执行,且这一系列操作的执行需要耗费一定时间,如安装 gdb 包时,在下载好安装包后,还需要逐个执行以下命令

且在大多数命令开始执行后,都需要一定的时间,等待命令执行完毕。若此时使用";"连接符连接这些命令,具体如下所示:

系统会自动执行这一系列命令。
又或者执行完ls -a命令后再执行ls -al命令:

(2)连接符“&&”
使用“&& ”连接符连接的命令,其前后命令的执行遵循逻辑与关系,只有该连接符之前的命令执行成功后,它后面的命令才被执行。
(3)连接符“||”
使用“||”连接符连接的命令,其前后命令的执行遵循逻辑或关系,只有该连接符之前的命令执行失败时,他后面的命令才被执行。
四、正则表达式
Python中学过了,这里就不写了,以后有时间的话在进行补充。
五、文本处理工具
1、grep
grep会从一个或多个文件中搜索与指定模式匹配的文本行,并打印匹配结果。 grep 命令的基本格式如下:
grep [选项] [模式] [文件名]以上格式中的模式是匹配规则,模式后的文件名用于指定搜索目标,文件名可以有多个,其间以空格分隔,模式前的选项用于对模式进行补充说明。
常用选项如下表:
选项 说 明 -c 只输出匹配行的数量,不显示匹配的内容 -i 搜索时忽略大小写 -h 当搜索多个文件时,不显示文件名前缀 -l 只输出匹配的文件名,不显示匹配的具体内容 -n 输出所有匹配的文本行,并显示行号 -s 不显示关于不存在或者无法读取文件的错误信息 -v 只显示不匹配的文本行 -w 匹配整个单词 -x 匹配整个文本行 -r 递归搜索,不仅搜索当前目录,还要搜索其各级子目录 -q 不输出任何匹配结果,以退出码的形式表示搜索是否成功,其中0表示找到了匹配的文本行 -b 打印匹配的文本行到文件头的偏移量,以字节为单位 -E 支持扩展正则表达式 -F 不支持正则表达式,按照字符的字面意思进行匹配 (1)匹配行首
正则表达式中的元字符“^”表示匹配行首,在使用 grep搜索文本时可以使用“~”符号进行行首的匹配。例如,查找文件/etc/sysctl.conf 中以“#”符号开头的文本行,并显示每行的行号,可使用如下命令
grep -n ^# /etc/sysctl.conf
~”符号还可以结合“$”符号搜索文件中的空白行,如搜索/etc/yum.conf文件中的空白行和非空白行,具体命令如下:
grep -c ^$ /etc/yum.conf # 空白行 grep -c ^[^$] /etc/yum.conf # 非空白行 # 解释: 在正则表达式中,^表示匹配行的开头,$表示匹配行的结尾。而[^$]表示匹配除了行尾之外的任意一个字符。 因此,正则表达式^[^$]可以匹配以非空字符开头的行。 -c选项用于统计匹配行的数量并输出
(2)设置大小写
使用-i选项可以使用 grep 命令不区分大小写,利用[]符号也可以实现这一功能。例如,在/etc/yum.conf文件中搜索This和this关键字,可以使用如下命令:
grep -n [Tt]his /etc/yum.conf
如果不区分大小写查找"this"字符串,可以使用如下命令:
grep '[Tt][Hh][Ii][Ss]' /etc/yum.conf
(3)转义字符
如果匹配的目标字符串中包含元字符,则需要利用转义字符
\屏蔽它们。例如,要搜索包含"seu.edu.cn"字符串的行,由于"."符号是元字符,因此需要在"."符号前加上""符 号进行转义,否则它会把"."符号匹配成任意字符。横杠(-)字符比较特殊,虽然它不属于正则表达式元字符,但是,由于“- ”字符是引出 grep命令的选项的特殊字符,因此当模式以“- ”字符开头时,也需要用转义字符将其转义。
接下来通过一个案例来演示转义字符的用法,在当前目录下有文件 chapter3-3.txt, 文件内容如下所示:
abcdef --- #$123在此文件中查找"---"文本行,可以使用如下命令:
grep '\-\{3\}' chapter3-3.txt # 解释: '-{3}'是一个正则表达式,用于匹配连续出现三次的破折号'---' 为了将-转义,所以整个正则表达式用一对单引号''引起来。 。。。。。。。不理解。。。
在这个命令中如果"-"符号前没有加转义字符,则会报错.

“- ”符号前没加加转义字符,结果 grep 将模式解析为选项,Shell 提示无效选项错误,如果不加单引号,会报两种错误。
grep命令族
随 着 Linux 的发展,grep 命令也在不断完善。到目前为止,grep 命令族已经包括 grep、 egrep 以及 fgrep 3 个命令。
egrep 是 grep 命令的扩展,它使用扩展正则表达式作为默认的正则表达式引擎,与grep -E 等价。
fgrep命令是 fast grep的缩写,它不支持正则表达式,因为在此命令中,所有字母都被 看作单词,也就是说,在 fgrep命令中,所有正则表达式中的元字符都被视为一般字符,仅仅 拥有其字面意义,不再拥有特殊意义。 fgreo 与 grep -F 是等价的。
2、sed
sed(stream editor)是一个非交互式的文本处理命令,它可以对文本文件和标准输入进行编辑。标准输入可以来自键盘、文件重定向、字符串、变量,甚至来自管道的文件。 sed 在 处理文本数据时,会将读取到的数据复制到缓冲区,在缓冲区中对数据进行处理,处理完成之后再输出到屏幕。其中,这个缓冲区又被称为模式空间,其工作原理如图所示。

在处理完一段文本之后,sed 会接着处理下一段,这样不断重复,直到文件末尾。当编 辑命令太过复杂、文件太大、文本处理需要执行多个函数时都可以使用 sed 命令对文本数据 进行处理。与 Vi 等其他文本编辑器相比,sed 可以一次性处理所有的编辑任务,可极大地 提升工作效率,节约用户时间。
sed 的基本命令格式如下所示:
sed [选项] 'sed 编辑命令' 输入文件在上述语法格式中,sed 编辑命令要用单引号括起来。 sed 命令的常用选项如表所示:
选项 含 义 -n 关闭默认的模式空间的输出 -e 将下一个字符串解析为命令,如果只传递一个命令,则可以省略此选项 -f 编辑脚本内容,表明正在使用脚本 -r 在脚本指令中使用扩展正则表达式 -i 直接修改原文件,此选项要慎用 sed编辑命令是对标识的文本进行处理,如打印、删除、追加、插入和替换等,sed 提供了 极为丰富的编辑命令,如表所示。
选项 含 义 p 打印匹配行 = 显示文件行号 a\ 在定位行号之后追加文本信息 i\ 在定位行号之前插入文本信息 d 删除定位行 c\ 用新文本替换定位文本 S 使用替换模式替换相应模式 r 从一个文件中读文本 w 将文本写入到一个文件 q 第一个匹配模式完成后退出 l 显示非打印字符 {} 在定位行执行命令组 n 读取下一个输入行,用下一个命令处理新的行 g 将保持缓冲区的内容复制到模式缓冲区 G 将保持缓冲区的内容追加到模式缓冲区 y 变换字符(不能对正则表达式使用y选项) h 将模式缓冲区的文本复制到保持缓冲区 H 将模式缓冲区的文本追加到保持缓冲区 了演示 sed命令的使用,编写一个文本文件 poem 作为待处理的文本文件,文件内容 如下所示:
#This is a poem# For rain =============================== Rain is falling all around, It falls on field and tree, It rains on the umbrella here, And on the ships at sea. by R. L. Stevenson,1850-1894在接下来 sed处理文本的过程中,如果没有特殊说明,均是指 poem 文件。
在命令行中可以使用sed命令直接对文本进行处理,如输出 poem 文件的内容,命令如下所示:
sed '=' poem
以上示例的命令中符号“=”是编辑命令,用于显示行号。需要注意的是,sed 的编辑命令可以加单引号也可以不加,与其他模式或命令结合使用时也是如此。
(1)追加文本
sed 的编辑命令
a\用于追加文本,它可以将指定的一行或多行文本追加到指定位置。 指定位置以匹配模式"/pattern/"或行号的形式给出,如果不指定地址,sed 默认放置到每一 行后面。实现文本内容追加功能的 sed 命令格式如下:
sed '指定地址 a\text' 输人文件以在poem 文件中的“For rain"后追加新的文本"add a new line!!!”为例进行说明,具体命令如下:
sed '/For rain/a\add a new line!!!' poem
由输出结果可以看出,追加成功。同样,也可以用脚本来实现文本的追加,编写脚本add.sh,内容如下所示:
/For rain/a\ we add a new line!!! /==/a\ add anothernew line!!!脚本add.sh 中使用编辑命令 a\实现追加。如果追加的文本有多行,可以使用反斜杠 “\”完成换行。脚本编写完成后,在命令行使用 sed命令调用脚本,方可完成追加。
sed -f add.sh poem
对比原 poem 文件与本次的输出结果可知,在双横线前后分别添加了新的文本,
以上实现的追加操作只是在标准输出中对输出结果进行了追加,并没有将这些新文本添加到原始文件 poem 中。如果要修改原文件,需要使用-i选项,命令如下所示:
sed -f add.sh -i poem(2)删除文本
如果是要删除某一文本行,可以使用编辑命令 d。 以删除 For rain 为例,具体命令如下:
sed /For rain/d poem执行不同的操作可以使用不同的编辑命令,sed 的编辑命令有很多,但其实只要掌握很少一部分就能处理大多数情况。
add.sh脚本中没有指定命令解释器,因此需要调用相应的命令来执行脚本。如果在脚本中指定命令解释器,则赋予脚本可执行权限后,可直接在命令行执行脚本。例如,修改 add.sh 脚本文件,在脚本中指定命令解释器。
修改后的 add.sh 脚本,第一行以
#!符号开头,后面是解释器的路径,即指定命令解释器,这一点与 Shell脚本的格式是一样的,关于Shell脚本的语法格式将在后面讲解。命令解释器一般是在/bin 目录下。如果读者不知道 sed 在哪个目录下,可以使用
which sed命令获知。
sed使用-f选项表示正在调用脚本文件, -f选项在脚本中必不可少,若无此选项,则执行脚本时将报错。赋予 add.sh 脚本执行权限,然后执行脚本,在执行脚本时仍然需要加上文件名。
add.sh内容修改如下:(sed后面的-f选项不能漏了!!!)
#!/usr/bin/sed -f /For rain/a\ we add a new line!!! /==/a\ add anothernew line!!!
在以后的学习过程中,如果需要对文本进行多处修改,最好使用脚本而不是命令。
3、awk
awk 不仅是一种强大的文本处理工具,也是一门编程语言。
awk 在读取分析数据时,从头到尾逐行扫描文件内容,寻找与指定模式匹配的行,并对匹配出的文本行进行处理。简言之,awk 的工作流程分为模式匹配和处理过程两步。
在匹配的过程中,如果没有指定匹配模式,则默认匹配所有数据。 awk 每读取一行数 据,都会对比该行是否与给定的模式相匹配,如果匹配,则对数据进行处理,否则不做任何处 理。如果没有指定如何处理内容,则把匹配到的内容打印到终端。
awk 定义了两个特殊的模式: BEGIN 和 END。BEGIN放置在读取数据之前执行,标识数据读取即将开始;END 放置在读取数据结束之后执行,标识数据读取已经完毕。
awk 的工作流程如图所示。

awk 命令的基本格式如下所示:
awk [选项] pattern {actions} 文件其中,pattern是匹配模式,actions是要执行的操作。以上语法表示当文本行符合 pattern指定的匹配规则时,执行 actions操作。 pattern和actions都是可选的,但至少要有一个。
如果省略pattern,则表示对所有的文本行执行 actions操作;如果省略 actions,则表示将匹配结果打印到终端。
awk 命令几个常用的选项:
选项 含 义 -F 指定以fs作为输入行的分隔符,默认的分隔符为空格或制表符 -v 赋值一个用户定义的变量 -f 从脚本文件读取awk命令 awk 中的匹配模式主要包括关系表达式、正则表达式、混合模式、BEGIN 和 END, 下面针对 这几种匹配模式进行详细讲解。为了演示 awk 对文本的处理,我们编写一个文本文件 scroe 用作 awk 的处理文件,文件内容如下所示:
zhangsan 88 76 90 83 lisi 100 69 89 84 xiaowang 68 87 92 63 xiaoming 77 70 88 90 lili 83 95 78 89 xiaohong 99 85 76 100文件 scores中的第一列为学生姓名,后面各列是各科成绩。在接下来的 awk 学习过程中,如无特殊说明,数据处理均以此文件为例。
(1)关系表达式
awk 提供了一组关系运算符,如表所示:
运算符 含 义 运算符 含 义 > 大于 == 等于 < 小于 != 不等于 <= 小于或等于 ~ 匹配正则表达式 >= 大于或等于 !~ 不匹配正则表达式 awk 允许用户使用关系表达式作为匹配模式,若目标文本包含满足关系表达式,当文本行满足关系表达式时,将会执行相应的操作。
下面通过一个案例来演示关系表达式的使用。
例1:用关系表达式作为 awk 命令的匹配模式,筛选出第一科成绩大于80分的同 学,编写 awk 脚本文件 chapter.sh,内容如下:
#!/bin/bash result=`awk '$2>80 {print}' scores` echo "$result"- 变量$2表示引用第二列的值;
- {print}表示打印匹配成功的文本行。
- 反引号``的作用是进行命令替换。(前面Shell中的符号中有讲。)
脚本的含义就是,将awk命令以字符串的方式赋值给变量result。echo输出变量result,由于awk命令是用反引号引起来的(进行了命令替换),所以输出时会直接执行反引号中的命令。
当然,也可以直接在命令行中输入命令
awk '$2>80 {print}' scores直接执行,效果是差不多的。赋予此脚本文件执行权限,执行该脚本,具体如下所示:

对比 scores文件中原始内容与输出结果,可知第二列(第一科成绩)值小于80的行已 经被过滤掉。
(2)正则表达式
awk 支持以正则表达式作为匹配模式,它的用法与 sed 相同。下面以使用正则表达式匹配首字符为 x 的行为例,展示 awk 的用法,具体如所示。正则表达式需要使用两个反斜杠//包起来。
例2:编写 chapter.sh 脚本文件,内容如下:
#!/bin/bash result=`awk '/^x/ {print}' scores` echo "$result"其中
/^x/表示筛选以字符x开头的文本行。赋予此脚本执行权限,执行该脚本,具体如下 所示:
由输出结果可知,以字符x 开头的文本行有3行。修改 chapter1.sh,使它可以匹配以zhang开头或li开头的文本行,修改后内容如下所示:
#!/bin/bash result=`awk '/^(zhang|li)/ {print}' scores` echo "$result"(zhang|li)表示匹配字符串zhang或李,上尖号^表示匹配行首。
(3)混合模式
awk 提供了3个逻辑运算符:&&、||、!。这3个运算符的含义如表3-7所示。
运算符 运算 范例 结 果 ! 非 !a 如果a为假,则!a为真如果a为真,则!a为假 && 与 a&.&b 如果a和b都为真,则结果为真,否则为假 || 或 a | |b 如果a和b有一个或一个以上为真,则结果为真;二者都为假,结果为假 如表3-7所示的逻辑运算符可以将多个表达式组合为一个模式,实现更复杂的功能。 下面通过一个案例来演示混合模式的使用,如例3-6所示。
例3:在文件 scores 中查找开头为 li 且第二列的值大于80 的文本行,编写 chapter2.sh 脚本文件,内容如下:
#!/bin/bash result=`awk '/^li/ && $2>80 {print}' scores` echo "$result"在这个脚本文件中有两个条件,第一是文本行以li开头,第二是文本行第二列的值大于80。赋予脚本执行权限,然后执行该脚本,结果如下所示:

由输出结果可知,满足条件的文本有两行。 awk 混合模式可以将多个条件组合起来完 成更精确的匹配,从这方面来说,它比 grep和 sed功能要强大。
(4)区间模式
awk 还支持区间模式,通过区间模式可以匹配几行连续的文本。类似于 sed命令中的 行号匹配,区间模式的格式如下所示:
(两个区间端点之间用逗号,分隔)
pattern1, pattern2以上格式的含义为:从与 pattern1匹配的文本行开始,到与 pattern2 匹配的文本行结束。使用区间模式匹配时,可匹配到多个连续的文本行。下面通过一个案例来演示区间模式的使用,如例4所示。
例4:使用区间模式匹配一段连续的文本行,编写 chapter4.sh 脚本文件,内容如下:
#!/bin/bash result=`awk '/^zhang/,$2==77 {print}' scores` echo "$result"在以上脚本中,第一个模式/^zhang/表示匹配以 zhang 开头的文本行;第二个模式 $2==77表示匹配第二列值为77的行。赋予脚本 chapter4.sh执行权限,执行该脚本:

由输出结果可知,它匹配到了包含前后两个模式在内的文本行之间的所有行。在使用 区间模式时, 一定要注意前后的边界,如果有多行文本符合指定模式,则 awk 会以第一次匹配到的文本行作为起始行。
(5)BEGIN模式和END模式
BEGIN 模式是一种特殊的内置模式,它的执行是在读取数据之前。 BEGIN 模式对应 的操作仅仅被执行一次,awk 读取数据之后,BEGINE 模式便不再有效。综上所述,用户可以将与数据文件无关,且在整个生命周期中只需要执行一次的代码放在BEGING 模式对的操作中,如自定义分隔符、初始化变量等。
END 模式与BEGIN 相反,它在 awk 读取完所有的数据后执行,该模式所对应的操作也只被执行一次。因此, 一般情况下,用户可以将许多善后工作放在 END 模式对应的操作中。
六、Shell脚本
0、Shell脚本的基本元素与执行方式
编写一个名为hello.sh 的 Shell脚本,具体内容如下:
#!/bin/bash echo "Hello,Bash Shell!" # 打印双引号中的字符串以上脚本中第一行以#!开头,用来指定命令解释器。在命令行执行该脚本时,当前Shell会根据此行内容搜索解释器的路径。如果发现了指定的解释器,则创建一个关于该解释器的进程,解释并执行当前脚本中的语句。
第二行代码是可执行语句,打印输出"Hello,Bash Shell"这一句话,这只是一行简单的 输出语句,用户可以根据需要加入逻辑分支。例如,if 结构语句、循环结构语句等编写的 Shell程序。
输出语句后面以“#”符号开头的是注释部分,在脚本程序执行时,这一部分会被忽略。
注释能增加 Shell脚本的可读性,便于阅读者理解脚本,因此,读者在编写脚本时,应养成加注释的好习惯。
Shell脚本的 执行方式有3种:
- 通过Shell脚本解释器(bash 或 sh)运行脚本;
- 通过 source运行脚本;
- 赋予 脚本执行权限,直接运行脚本。
下面分别对这3种方式进行介绍。
(1)通过 Shell脚本解释器(bash 或 sh)运行脚本。
这种方式是将脚本文件作为参数传递给解释器,在通过这种方式运行脚本的时候,不需要用户拥有执行该脚本文件的权限,只 要拥有文件的读取权限就可以。例如,使用 bash 或 sh 运行 hello.sh脚本,结果如下所示:

这种方式首先调用解释器,然后由解释器解释脚本文件,执行程序。它和 sed、awk命令执行相应脚本文件的原理是一样的。
(2)通过 source运行脚本。
source命令是一个 Shell内部命令,它可以读取指定的 Shell脚本,并且依次执行其中的所有语句。例如,使用 source 命令执行hello.sh 脚本,结果如下所示:

该命令只是简单地读取脚本中的语句,依次在当前 Shell 中执行,并没有创建新的子Shell进程,脚本中所创建的变量都会保存到当前的 Shell中。
(3)赋予脚本执行权限,直接运行脚本。
关于这种方式,前面在介绍 sed和 awk 时已经提及过,此处不再赘述。它的执行过程如下所示。
./hello.sh . hello.sh # 两者没什么区别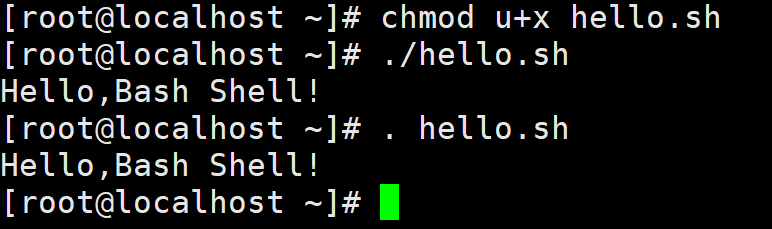
1、判断结构
(1)if结构
if语句是最简单的判断结构,它对条件进行判断,如果判断结果为真,则执行下面的命令,其判断格式有两种形式:
if expression then 命令语句 fi # 或 if expression; then 命令语句 fi在上述格式中,expression 表示条件表达式,如果 expression后面没有“;”符号,则 then 要另起一行,若有“;”符号,则 then 要与 expression处于同一行,expression 后面要用“;”符 号隔开,且中间要有一个空格。最后的fi表示判断结构结束。
下面通过一个案例来演示 if结构的用法,如例1所示。
例1:编写 一个脚本test1.sh, 判断在当前目录下是否存在 一 个名为 name.yaml的文件,脚本内容如下:
#!/bin/bash if [ -e name.yaml ]; then echo "name.yaml exsit" fi在脚本中,表达式[-e name.yaml ]用于判断 name.yaml 文件是否存在, -e 是一个文件操作符,用于判断文件否存在。 then 与表达式在同一行,使用“;”符号分隔开。 如果条件为真,则会输出"name.yaml exsit!"。
注意:if条件中的中括号
[]和其括起来的-e name.yaml之间要用空格隔开!!!下面赋予脚本执行权限,执行该脚本,(当然,也可以使用bash test1.sh命令使用执行脚本。

(2)if/esle结构
if/else结构指如果满足条件,则执行then 后面的操作;如果不满足条件,则执行 else后 面的操作。例如,判断一个数是否等于100,如果等于,则执行 then后面操作;如果不等于, 则执行 else后面的操作。 if/else结构的格式如下所示:
if expression then 命令语句1 else 命令语句2 fi在上述格式中,如果 expression条件为真,则执行“命令语句1”,否则执行“命令语句2”。当然,then也可以与expression在同一行,使用“;”符号分隔开(;与then之间同样要有一个空格)。
下面通过一个案例来演示 if/else结构的用法,如例2所示。
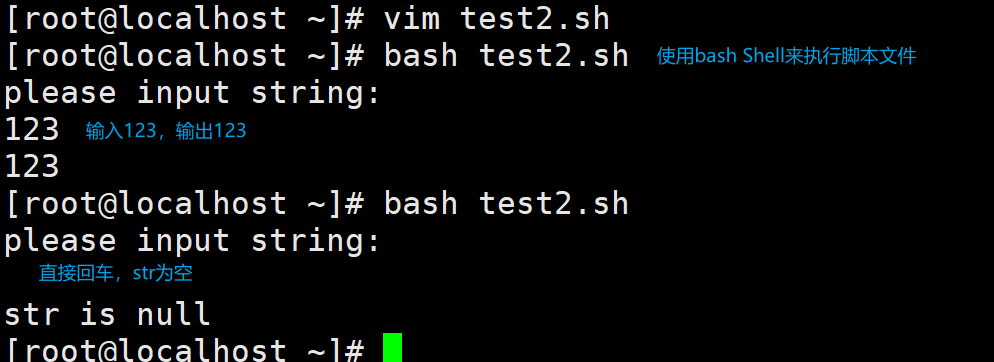
例2:编写一个脚本test2.sh, 用于从键盘读取用户输入的字符串,如果字符串为空,则输出为空;如果字符串不为空,则输出字符串,脚本内容如下所示:
#!/bin/bash echo "please input string:" # 将字符串中的内容输出到屏幕,起到一个提示的作用 read str # 读取键盘输入的字符,并赋值给变量str # 下面进行if条件判断 if [ -z "$str" ]; then # 判断变量str是否为空 echo "str is null" # str为空 else echo $str # str不为空,则输出str fi注:“#”后面的内容是注释,并不影响脚本的执行。
- -z用于判断变量的值是否为空,为空则为True。
- [ -z "$pid" ] 单对中括号变量必须要加双引号
- [[ -z $pid ]] 双对括号,变量不用加双引号
(3)if/elif/else结构
if/elif/else 结构可以进行多种情况的判断。例如,对一个学生的成绩进行判断,如果大 于90分则为 A, 否则判断是否大于80;如果大于80分则为 B,否则再判断是否大于70分;
如果大于70分则为 C, 否则为D。if/elif/else结构的格式如下所示:
if expressionl; then 命令语句1 elif expression2; then 命令语句2 elif expression3; then 命令语句3 ... else 命令语句n fi在上述语法格式中,如果 expression1 条件不成立,则直接进行 expression2 条件的判 断;如果 expression2条件不成立,则直接进行 expression3条件的判断;以此类推,直到条件 表达式成立,执行相应的命令语句,或者直到所有的条件都判断完毕,所有条件都不成立,则执行 else后面的命令语句。
下面通过一个案例来演示 if/elif/else结构的使用,如例3所示。
例3:编写一个脚本test3.sh, 从键盘读取学生成绩,判断学生成绩级别,脚本内容如下:
#!/bin/bash echo "p;ease input score(0-100):" read score # 读取键盘输入,并赋值给变量score if [ $score -lt 0 -o $score -gt 100 ]; then # 判断分数是否在0-100内 echo error score # 不在0-100,则输出error score elif [ $score -ge 90 ]; then echo A # 分数大于等于90,输出A elif [ $score -ge 80 ]; then echo B elif [ $score -ge 70 ]; then echo C else echo D # 分数低于70输出D fi
(4)case结构
case结构也用于进行判断,只是它的判断条件只能是常量或正则表达式,其语法格式如下所示:
case"$var" in var1) 命令语句1;; # 注意:语句后面有两个分号 var2) 命令语句2;; ... *) 命令语句n;; esac在上述语法格式中,var 变量会与 var1、var2、 ……逐一进行比较,如果 var与 varl 匹 配,则执行命令语句1,然后跳转到 esac结束语句;如果 var与 var2 匹配,则执行命令语句 2,然后跳转到 esac结束语句;如果所有的变量都没有匹配成功,则会匹配“*”符号,执行它 后面的命令语句n,然后接着执行 esac结束语句。
下面通过例4来演示case结构的使用。
例4: 编写一个脚本 chapter3- 11.sh, 让用户输入一个整数值,根据输入的整数值判断是周几,脚本内容如下:
#!/bin/bash echo "please input weekday(1-7):" read weekday case "$weekday" in 1) echo Monday;; 2) echo Tuesday;; 3) echo Wednesday;; 4) echo Tursday;; 5) echo Friday;; 6) echo Saturday;; 7) echo Sunday;; *) echo error day;; esac
2、循环结构
(1)for循环
for循环是Shell编程中最常用的循环,它通常从一个列表中读取元素赋予变量,然后 执行循环体中的命令语句,执行完毕之后再次从列表中读取元素赋予变量,再次执行循环体 中的命令语句,如此循环,直到列表中的元素被读取完毕,其语法格式如下所示:
for var in {list} do 命令语句 done在上述语法格式中,for var in {list}是循环条件,do…done 之间是循环体。 for循环在 执行时,会从列表中取第一个元素赋予var 变量,执行循环体中的命令语句;接着从列表中 读取第二个元素赋予 var 变量,执行循环体中的命令语句,直到列表中的值被读取完毕,循环结束。
下面通过一个案例来演示 for循环的使用,如例1所示。
例1:编写一个脚本test1.sh, 循环输出1~5这5个数值,脚本内容如下
#!/bin/bash for var in 1 2 3 4 5 do echo $var done
由输出结果可知,该脚本成功输出了1~5这5个数值。在 for循环中,如果列表中的元素是连续的整数,则中间可以使用省略号,例如,test1.sh 脚本中循环列表还可以写成如下形式:
for var in {1..5} #相当于 for var in 12345当列表中有很多元素时,例如,1~100,就可以使用这种方式来简写。除此之外,for循 环中的列表还可以按步长进行跳跃,例如,列表中元素是1~100,每次只读取奇数,则可以2 为步长跳跃读取,代码如下所示:
for var in {1..100..2} # 以2为步长,从1开始读取1~100之间的元素除此之外,还可以在脚本执行时从命令行给脚本传递参数。在前面学习了 Shell 特殊变量,这些特殊变量就是用来管理查看脚本运行时的参数信息的,在脚本执行时,可以借助特殊变量向脚本传递参数。
Shell中的 for循环,除了使用列表外,还有类似C 语言风格的 for循环,格式如下所示
for ((expression1; expression2; expression3)) do 命令执行语句 doneexpression1 是初始化表达式,expression2是循环条件,expression3 是操作表达式。它们的执行过程与C 语言的for循环是相同的。由于C 语言风格的 for循环只适用于次数已知的循环,而且不适用于字符串、文件作为变量的循环,因此它在 Shell编程中较少使用,此处不再赘述。
(2)while循环
与for循环相比,while循环要简单一些。它只有一个判断条件,如果条件为真,则执行循环体中的命令语句;如果条件为假,则退出循环。 while循环格式如下所示:
while expression do 命令语句 done在上述语法格式中,如果 expression为真,则执行循环体;如果为假,则退出循环。在循环执行过程中,必须要有退出循环的条件以避免陷入死循环。
下面通过例2来演示 while循环的用法。
例2:编写一个脚本test2.sh, 循环输出1~5这5个数值,脚本内容如下
#!/bin/bash num=1 # 定义变量num=1 while (($num<=5)) # 循环条件 do echo $num # 条件为真,则输出num的值 let num++ # 调用let命令时num自增 done
除了自定义循环条件,while 循环也可以从命令行中传递参数。从命令行传递参数时,它常与 shift 命令组合在一起使 用,如例3所示。
例3:编写脚本test3.sh.sh, 使用 while 循环输出当前目录下的所有文件,要从命令行传递参数,脚本内容如下所示:
#!/bin/bash echo "The count of arguments is $#" echo "arguments list:" while [ $# -ne 0 ] do echo $1 shift done在该脚本中,第2行代码使用$#变量统计所有参数个数;第4行代码使用 while 循环逐个输出参数,循环条件是$#不为0,即参数个数不为0;第5~8行代码是循环体,逐个遍历参数。其中shift命令作用是将变量的值依次向左传递,在$1输出之后,它将下一个参 数$2传递过来,同时$#也会自动减1,每执行一次 shift 命令就会进行一轮替换,直到所 有参数都输出完毕。脚本执行结果如下:
bash test3.sh `ls` 反引号··的作用是进行命令替换,ls命令输出的结果作为脚本的参数。
(3)until循环
until循环的格式与 while 循环类似,但在判断循环条件时,只有循环条件为假才会去执行循环体;如果循环条件为真,则退出循环,其格式如下所示:
until expression do 命令语句 done在上述语法格式中,直到 expression条件成立才会退出循环,这一点与 for循环、while循环正好是相反的,读者要尤其注意。下面通过一个案例来演示 until循环的用法,如例4所示。
例4:编写脚本test4.sh, 使 用until 循环输出1~5这5个数值,脚本内容如下所示:
#!/bin/bash num=1 until [ $num -gt 5 ] do echo $num let num++ done在该脚本中,第3行代码中until循环条件是num 变量大于5,如果此条件不满足,则执行循环体输出 num 变量;如果此条件满足,则退出循环。

3、break与continue
在循环过程中,如果达到某一个条件需要退出循环,就需要使用循环控制符跳出循环, Shell中提供了两个循环控制符: break 和 continue。 下面针对这两个循环控制符进行详细 讲解。
(1)brak
break 用于强行退出循环,它会忽略循环条件的作用,退出循环之后,它接着执行循环之外的命令。 break 可以用在for循环、while循环、until循环中,在例4中通过 until循 环输出了1~5这5个数值。下面通过修改例4来演示 break 的用法,如例5所示。
例5:根据test4.sh编写test5.sh, 当 num 变量值为3时,退出循环,内容如下所示:
#!/bin/bash num=1 until [ $num -gt 5 ] do echo $num if [ $num -eq 3 ]; then # 判断num的值是否等于3 break # 如果等于3就退出循环 fi let num++ done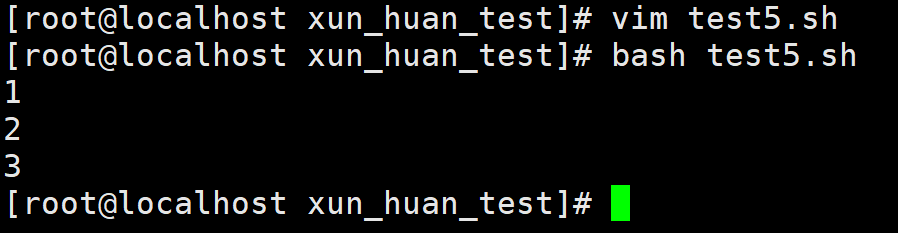
需要注意的 是,如果脚本中有多层循环,则 break 只能退出本层循环,无法退出外层的循环。
(2)continue
continue 用于跳过本次循环,接着执行下一次循环,它不会退出循环,只是跳过本次循环,循环会按照循环条件正常退出。下面通过一个案例来演示 continue的用法,如例6所示。
例6:编写一个脚本test6.sh, 输出1~50内可以被5整除的数,脚本内容如下:
#!/bin/bash for num in {1..50} do let temp=num%5 # 变量temp是num除以5的余数,用于判断num能否被5整除 if [ $temp -ne 0 ]; then # 判断temp是否等于0,不等于0,条件为真(-ne表示不等于) continue # 满足条件,num不能被5整除,跳过本次循环 fi echo $num done
需要学习的内容
LVM逻辑卷和RAID磁盘阵列
软件包管理
更改镜像源
离线安装pstree,含有pstree命令的工具包的名字不是pstree。
DVD安装
# yum软件包镜像源 ls /etc/yum.repos.d/ 查看 cat /etc/yum.repos.d/CentOS-Media.repo # CentOS-Base.repo这个是镜像仓库地址的文件 将DVD挂载到这几个任意一个目录 baseurl=file:///media/CentOS/ file:///media/cdrom/ file:///media/cdrecorder/ 创建/media/cdrom/这个目录 mkdir /media/cdrom 将dvd挂载到这个目录 mount /dev/cdrom /media/cdrom/ 安装命令 yum --disablerepo=\* --enablerepo=c7-media [command] yum --disablerepo=\* --enablerepo=c7-media search ifconfig 使用seatch命令查找这个目录的软件包名然后再安装shell
sed
ifconfig | sed -n '2p' | sed 's/^.*inet //' | sed 's/netmask.*$//' # 将ens33的ipv4地址过滤出来 # 为什么全部匹配了 [root@localhost ~]# ifconfig | sed -e 's/inet//' -e 's/netmask.*$//p' -n 192.168.1.71 127.0.0.1 192.168.122.1 awk 'BEGIN{printf "%s\t\t%s\t%s\t%s\t%s\n","姓名","语文","数学","英语","体育"}'{print} score awk 'BEGIN{printf "%s\t\t%s\t%s\t%s\t%s\n","姓名","语文","数学","英语","体育"}{printf "%s\t%d\t%d\t%d\t%d","$1","$2","$3","$4","$5"}' score实验
1、通过sed和awk过滤IP地址(ifconfig) [root@localhost ~]# ip a |sed -n '9p' | sed -n 's/^.*inet //p' | sed -n 's/ .*$//p' 192.168.1.71/24 [root@localhost ~]# ip a | awk 'NR==9{print $2}' 192.168.1.71/24 # 过滤mac地址 过滤出mac的第三个部分 [root@localhost ~]# ip a | awk 'NR==8{print $2}'|awk -F ":" '{print $3}' 29 # awk的符号 $0 表示一整行 -F "[ :]" 以空格或冒号作为分隔符 $2~/正则/ 将第二列中的内容以正则表达式进行匹配过滤 从/etc/passwd中显示出新添加的用户信息 [root@localhost ~]# cat -n /etc/passwd | awk -F ":" '$3>=1000 && $3<65534' 44 abc:x:1000:1000:abc:/home/abc:/bin/bash 45 aaa:x:1001:1001::/home/aaa:/bin/bas 2、shell脚本 #!/bin/bash num=q until [ $num -gt 5 ] do echo $num let num++ done 使用./或.空格或source执行,需要添加执行权限 也可以使用bash执行扩展正则表达式
grep
转义字符那部分的这个命令不理解
grep '\-\{3\}' chapter3-3.txtDHCP实验
1、在vmware中,编辑->虚拟网络编辑器
选择仅主机模式下,取消勾选DHCP。点击确定。

2、准备两台虚拟机,一台是Linux作为DHCP服务器,另一台windows或Linux作为客户机去验证DHCP服务器能否正常工作。(这里选择windows作为客户机)
将windows的网络适配器设置为仅主机模式。
3、将Linux的DVD镜像连接到虚拟机
将作为DHCP服务器的Linux虚拟机网络适配器设置为仅主机模式,并将Linux的DVD镜像连接到虚拟机。
4、在物理机中打开网络适配器

这里的IP地址是作为仅主机模式的虚拟机的网关来使用的(经过实验,其实并不一定是虚拟机的网关。这个IP的作用是,当虚拟机和物理机之间互相通信时,就是通过这个虚拟网卡的这个IP来进行通信的)。
配置完成后点击确定。最好再禁用再启用一下。
5、配置DHCP服务器为静态IP
虚拟机IP地址要在“虚拟网络编辑器”那里的子网的范围中。
查看虚拟机网络编辑器中的仅主机模式的子网
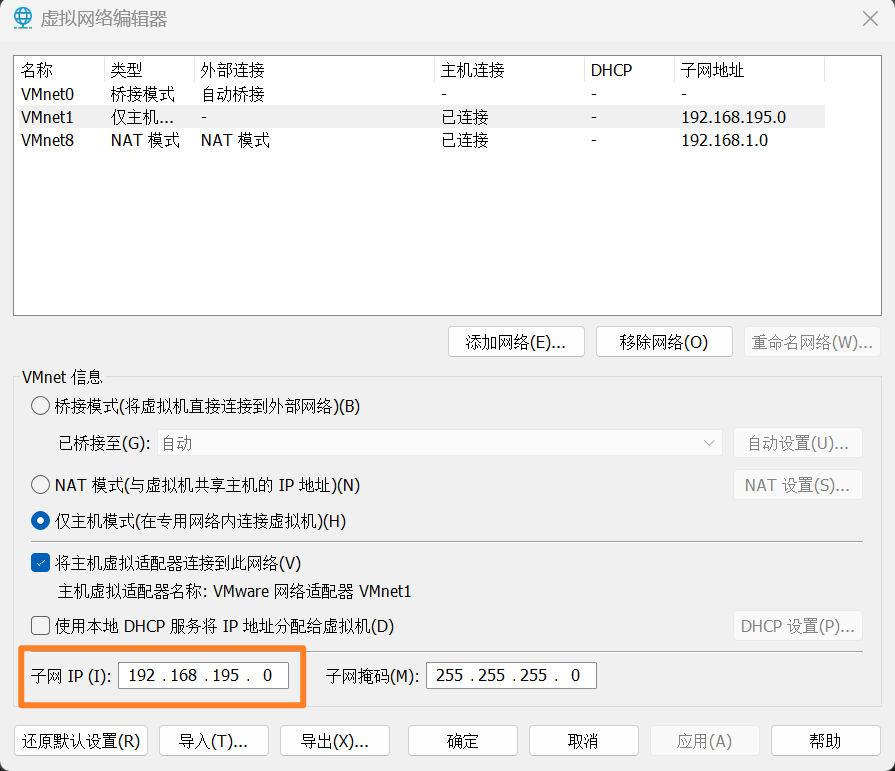
这的子网为192.168.195.0,掩码是255.255.255.0,所以仅主机模式下的虚拟机可以使用的IP地址是192.168.195.1到192.168.195.254。
图形化:

字符界面:
# 修改配置文件 vim /etc/sysconfig/network-scripts/ifcfg-ens33
5、挂载DVD光盘,安装DHCP
在DHCP服务器中,
使用cat查看/etc/yum.repos.d/CentOS-Media.repo文件的内容,
[c7-media] name=CentOS-$releasever - Media baseurl=file:///media/CentOS/ file:///media/cdrom/ file:///media/cdrecorder/选择baseurl后面的三个路径中的一个,将DVD镜像文件挂载到目录上。(这里选择cdrom目录
使用ls命令查看cdrom目录是否存在。ls /media/

不存在,则使用mkdir命令创建目录。mkdir /media/cdrom

使用mount命令将镜像文件挂载。mount /dev/cdrom /media/cdrom/

使用安装命令yum --disablerepo=* --enablerepo=c7-media [command]进行安装dhcp。
yum --disablerepo=\* --enablerepo=c7-media install dhcp两台虚拟机都安装不了。。。一个是找不到软件包,一个是安装过程中出现问题,用的镜像都是同一个,而且都成功挂载了。
使用在线方式安装,重新该一下网络配置。。。。

6、修改dhcp配置文件
使用cat查看/etc/dhcp/dhcpd.conf配置文件,内容如下:
# # DHCP Server Configuration file. # see /usr/share/doc/dhcp*/dhcpd.conf.example # see dhcpd.conf(5) man page #根据配置文件内容的提示,查看示例文件。cat /usr/share/doc/dhcp*/dhcpd.conf.example
随便找一段以subnet开头的内容,复制
subnet 10.254.239.32 netmask 255.255.255.224 { range dynamic-bootp 10.254.239.40 10.254.239.60; option broadcast-address 10.254.239.31; option routers rtr-239-32-1.example.org; }打开/etc/dhcp/dhcpd.conf配置文件,将复制的内容粘贴到里面,并进行一些修改。

修改完成后重启dhcp服务
systemctl restart dhcpd7、使用客户机检验dhcp服务器能否正常工作
在windows虚拟机中,打开网络适配器,进行如下配置。

配置完成后,点击确定。然后右键禁用Ethernet0,再右键启用。
打开cmd命令行,使用ipconfig命令查看ip地址,是否自动获取了。

自动获取了IP地址,192.168.195.110,实验成功!
-