翻译:MySQL InnoDB Cluster - Navigating the Cluster
本文是对这篇文章MySQL InnoDB Cluster - Navigating the Cluster[1]的翻译,翻译如有不当的地方,敬请谅解,请尊重原创和翻译劳动成果,转载的时候请注明出处。谢谢!
当我们管理InnoDB Cluster时,一件非常重要的事情就是了解集群处于什么样的状态,特别是要了解如何解释集群状态的报告,以及如何从各种具体失败的故障场景中恢复。
组复制成员状态
组成员所处的状态取决于您是直接查询该成员还是通过其他成员间接查询该成员。
成员本身可见的状态:
OFFLINE
RECOVERING
ERROR
ONLINE
对其他成员可见的状态:
RECOVERING
UNREACHABLE
ONLINE
当MySQL实例正在运行但是其尚未加入任何组时,它就处于OFFLINE的状态。一旦它加入一个组后,MySQL实例与该组的其它节点/成员同步数据时,它将切换为RECOVERING。一旦数据同步恢复完成(分布式恢复完成),它最终切换到ONLINE状态. 如果数据同步由于某些原因失败时,节点则会切换到ERROR状态.
如果一个ONLINE的成员停止响应其他成员时(因为MySQL实例崩溃、网络问题、极高的负载、超时等),其状态将切换为UNREACHABLE。如果该UNREACHABLE成员在超时之前没有恢复,它将被其它成员从组中剔除/驱逐,因此在命令cluster.status()的输出中状态显示为MISSING。驱逐成员的过程是通过投票完成的,因此只有在有足够的成员并达到法定人数的情况下才会发生。

组或副本集状态
下图概述了组呈现的可能状态以及状态转换是如何发生的。
实线过渡线显示您可以在每种状态下执行的 MySQL Shell 命令,而虚线则是在我们控制之外触发的事件。
为了减少混乱,图中省略了一些可能性。例如,只要有法定人数,您就可以在任何状态下执行大多数命令,例如addInstance()或rejoinInstance()命令
cluster.status()命令显示的组状态信息:
OK –当所有成员都属于ONLINE状态并且有足够的冗余来容忍至少一个节点故障时显示。
OK_PARTIAL –当一个或多个成员不可用,但仍有足够的冗余来容忍至少一个节点故障时。
OK_NO_TOLERANCE –当有足够的ONLINE成员达到法定人数,但没有冗余节点时。两个成员组成的团体没有冗余,因为如果其中一个成员变成了UNREACHABLE,另一个成员就无法单独形成大多数;
这意味着您将遇到数据库中断(database outage)情况。但与单个成员组不同的是,至少您的数据在至少一个节点上仍然是安全的。
NO_QUORUM – 一个或多个成员可能仍然是ONLINE,但不能达到法定人数。在此状态下,您的集群不能写入,因此无法执行事务。但是,只读查询仍然可以执行,并且您的数据是完整且安全的。
UNKNOWN – 如果您从一个不是ONLINE或RECOVERING状态的实例执行命令status()时,则会显示此状态。在这种情况下,请尝试连接到其他成员。
UNAVAILABLE – 该状态在图中显示,但不会出现在cluster.status()命令显示中。在这种状态下,该组的所有成员都是OFFLINE。他们可能仍在运行,但他们不再是该集群的一部分。例如,如果所有成员重新启动而没有重新加入集群,则可能会发生这种情况。

InnoDB集群的状态转换图。(PDF版[2])
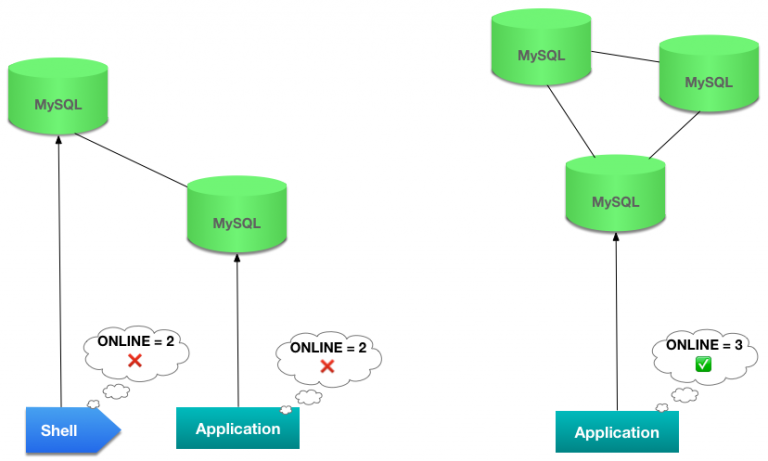
组分区
一种特殊场景是组分区,虽然这种情况很少见,但可能会造成混乱,有时甚至很危险,即组的成员实际上分为2个组或多个组。例如,如果您的成员位于不同的网络中并且他们之间的通信中断,则可能会发生这种情况。在这种情况下,所有成员都是ONLINE,但一个组的成员将被另一个组成员视为UNREACHABLE,反之亦然。由于需要多数,只有一个组(最多一个组)能够接收数据更新,从而保持数据库的一致性。
但是,当使用cluster.forceQuorumUsingPartitionOf()命令时,就像下面所解释的那样,您必须小心,不要让组成员处于这种情况。如果遇到这种情况,您可能会创建2个单独的组来分别接收更新,这将导致您的数据库独立处理事务并使其处于不一致的状态。

5个成员全部ONLINE
5人成员分裂为两组
从失败中恢复
以下场景是发生故障时可能遇到的一些最常见情况。我们解释了如何识别它们以及如何在MySQL Shell中使用InnoDB Cluster API 来恢复它们。
服务器重新启动
如果mysqld 由于任何原因(实例崩溃、预期重启、重新配置等)重新启动,那么当它恢复时,它将不再位于该组/集群中。它需要重新加入它,这在某些情况下可能必须手动完成。为此,您可以使用cluster.rejoinInstance()命令将MySQL实例加入回组中。它用的参数是MySQL实例的URI。
示例:
cluster.rejoinInstance("[email protected]")
失去法定人数
如果副本集的大量成员变成UNREACHABLE,以至于它不再拥有多数成员,则它将不再拥有法定人数,并且无法对任何更改做出决定。这包括用户事务,还包括组拓扑的更改。这意味着,即使成员从UNREACHABLE状态恢复了, 该成员依然被阻止,无法重新加入该群组。
要从这种情况中恢复,我们必须首先取消该组(unblock the group),方法是将其重新配置,仅考虑当前ONLINE的成员并忽略所有其他成员。为此,用cluster.forceQuorumUsingPartitionOf()这个命令 传入复制集中中一个ONLINE的成员的URL作为参数。所有可见的ONLINE成员都将添加到重新定义的组中。
请注意,这个命令是一个危险的命令。如上所述,如果您的组中碰巧有一个分区,您可能会意外地出现裂脑,这将导致数据库不一致。在使用此命令之前,请确保所有成员都是UNREACHABLE,并且状态为OFFLINE。
例子: cluster.forceQuorumUsingPartitionOf("[email protected]")
所有成员OFFLINE
cluster.forceQuorumUsingPartitionOf()命令要求至少有一个实例一直处于ONLINE并且属于该组。如果不知何故,您的所有成员都是OFFLINE状态,则只有从单个种子成员中再次“引导”该组,您才能恢复该组。要执行此操作,您需要在选中的种子实例上使用命令dba.restoreFromCompleteOutage(),然后在剩余成员上使用命令rejoinInstance(),直到集群完全恢复为止。
注意:此命令从 MySQL Shell 1.0.7 开始可用。
结论
MySQL InnoDB Cluster意在为拥有不同知识和经验水平的 MySQL 用户提供高可用性。虽然cluster.status()命令可以让您一目了然地监控集群的状态,但如何了解原理非常重要,这样您就知道何时需要该采取哪些措施来确保 MySQL 数据库保持最佳运行状态。
参考资料
1: https://dev.mysql.com/blog-archive/mysql-innodb-cluster-navigating-the-cluster/,
[2]pdf: https://dev.mysql.com/blog-archive/mysqlserverteam/wp-content/uploads/2016/12/AvailabilityStateMachine.pdf
